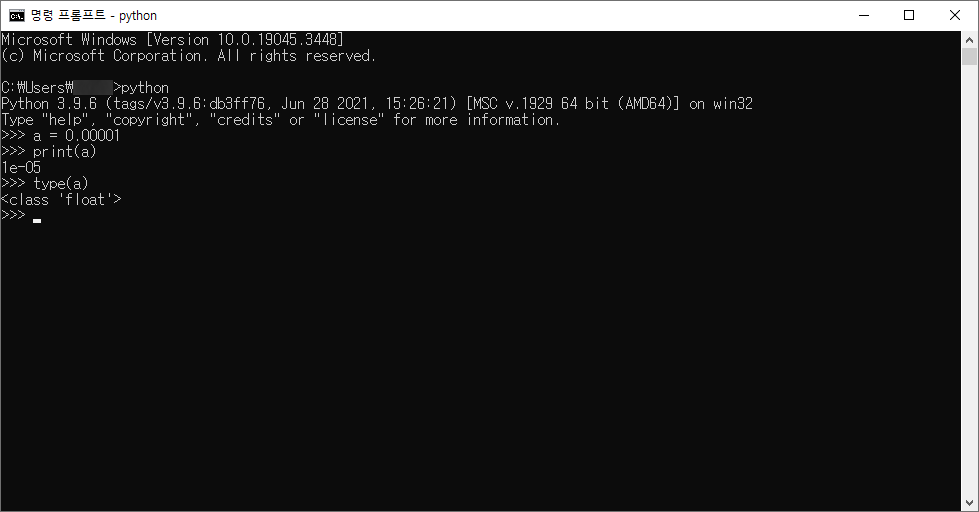
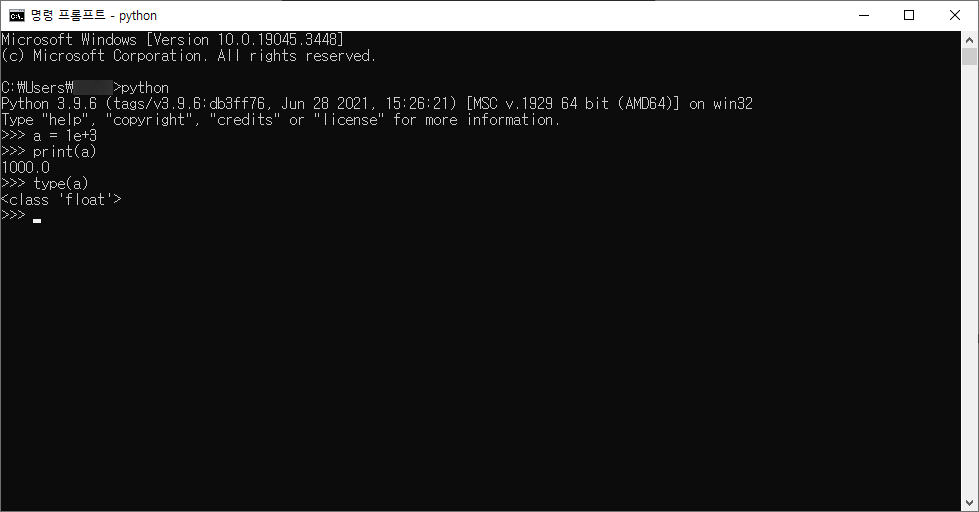
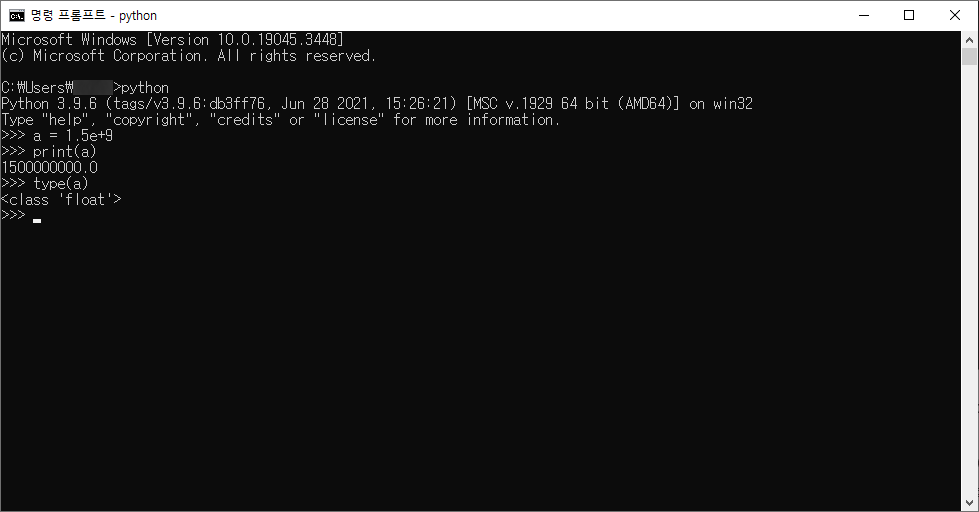
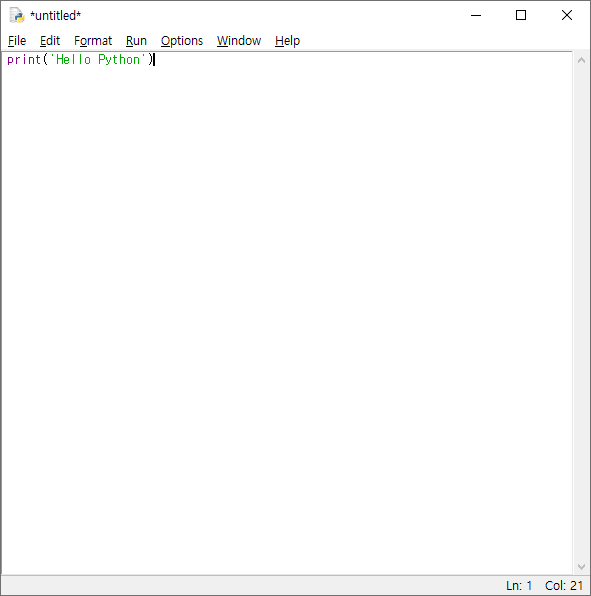
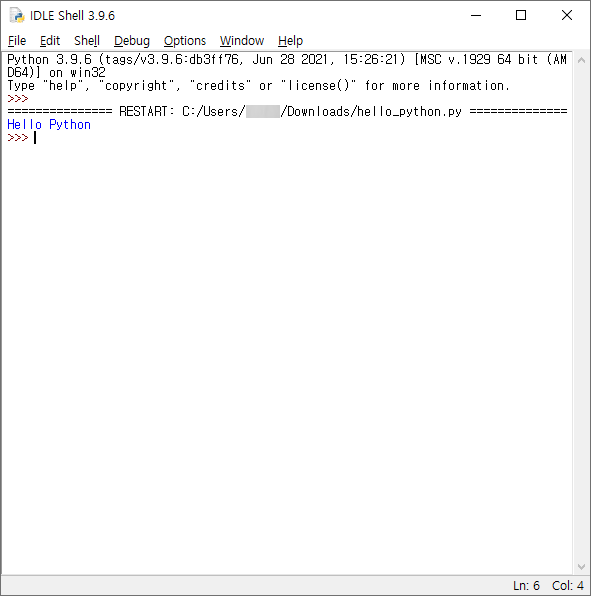
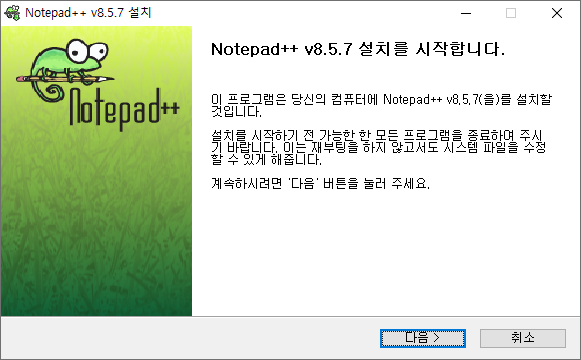
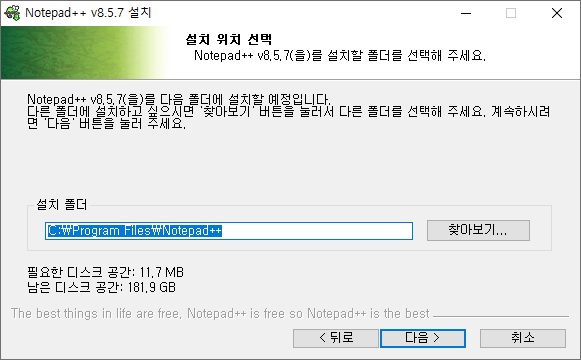
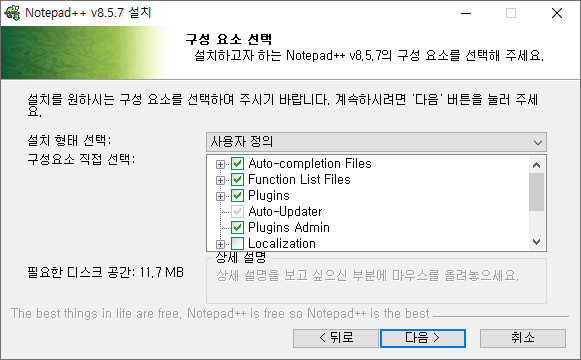
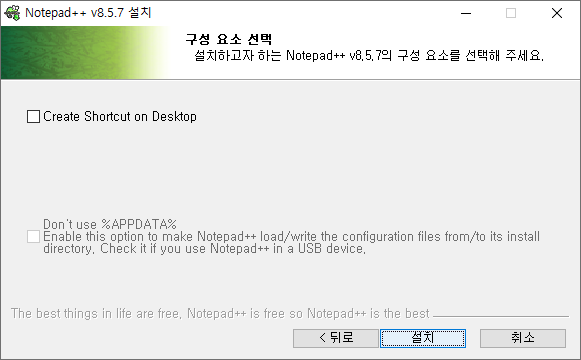
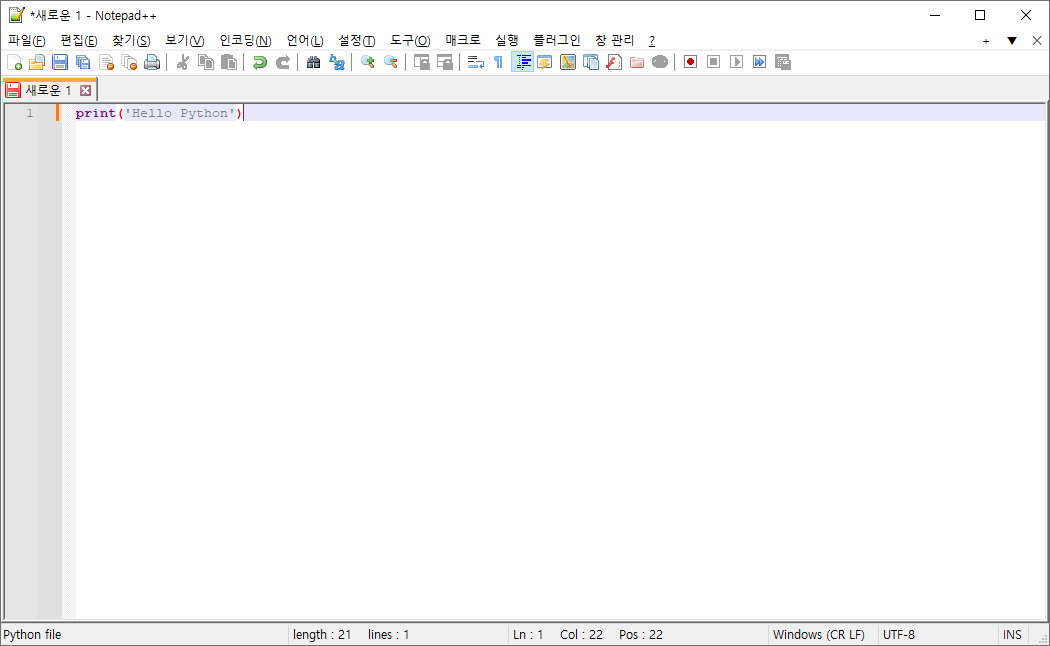
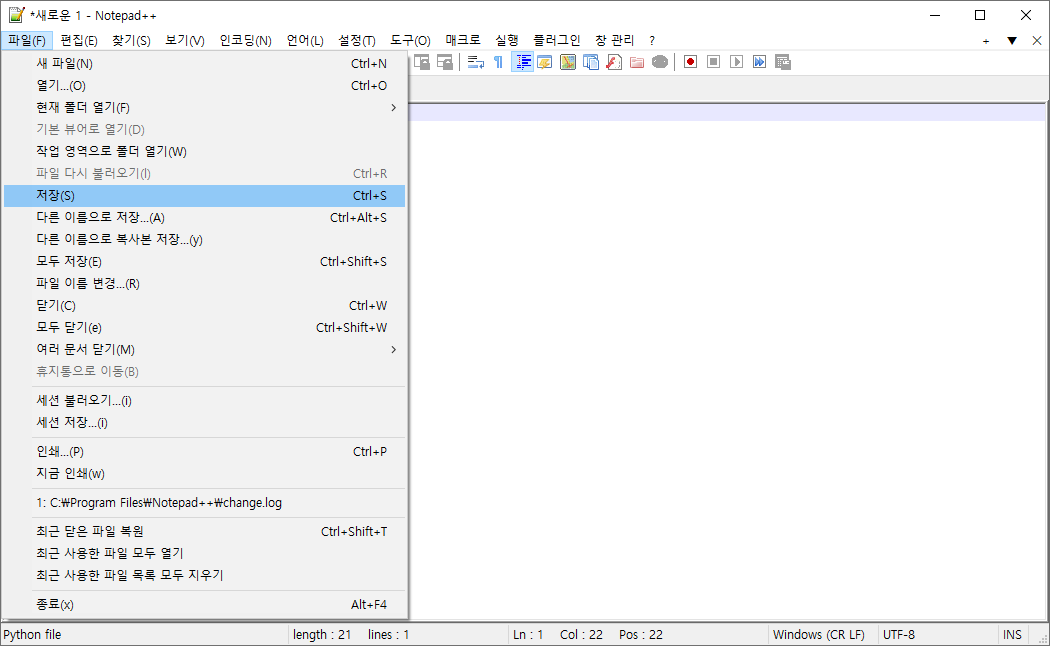
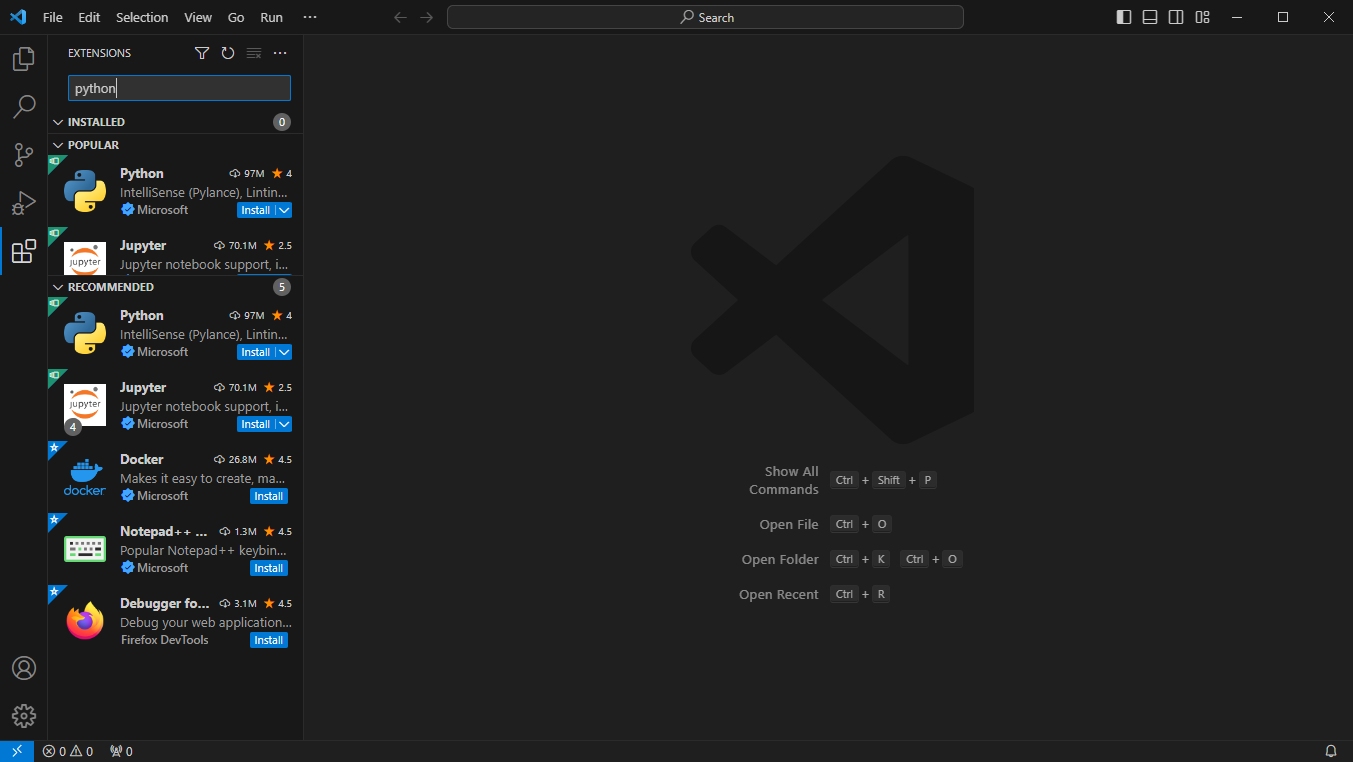
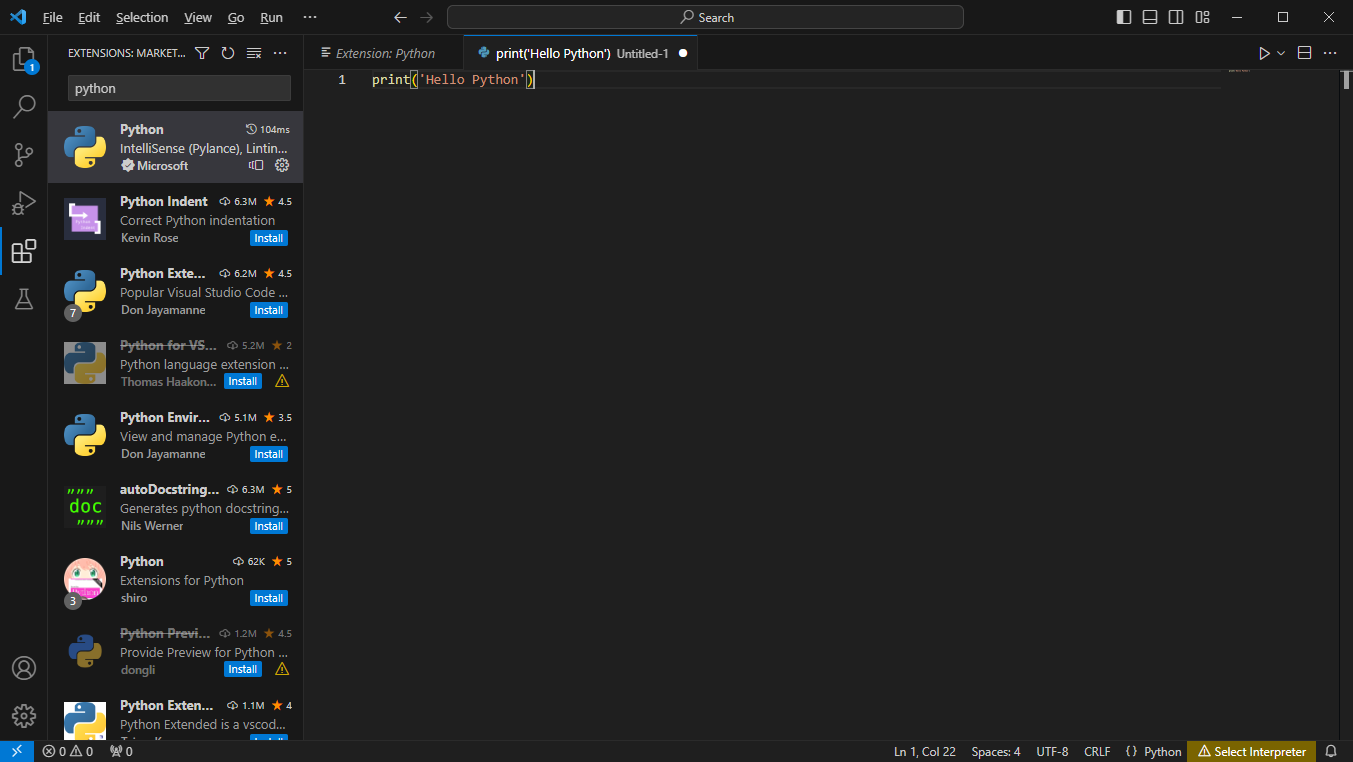
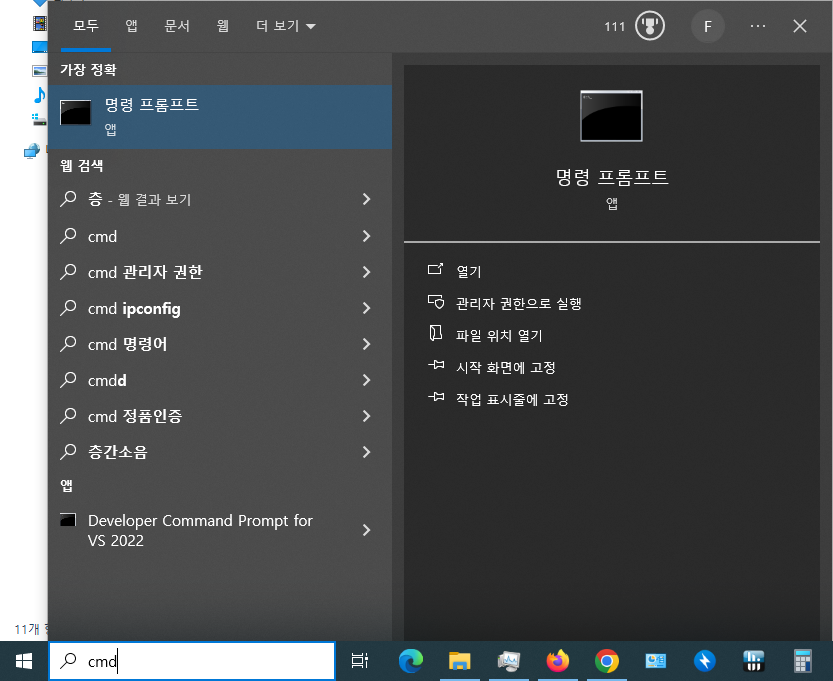
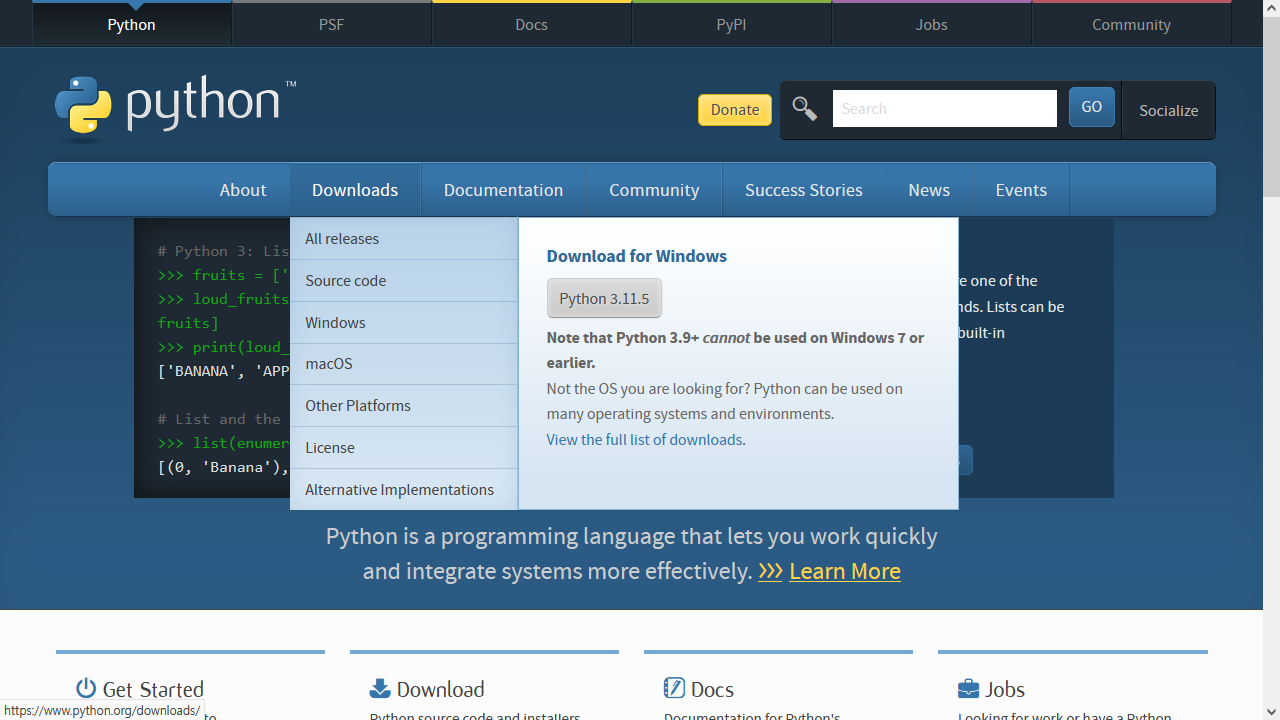
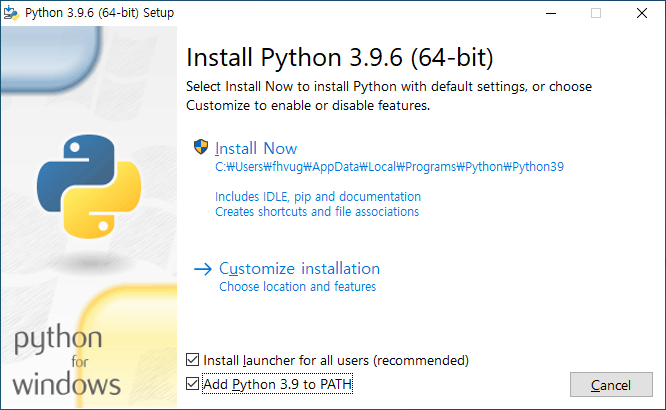
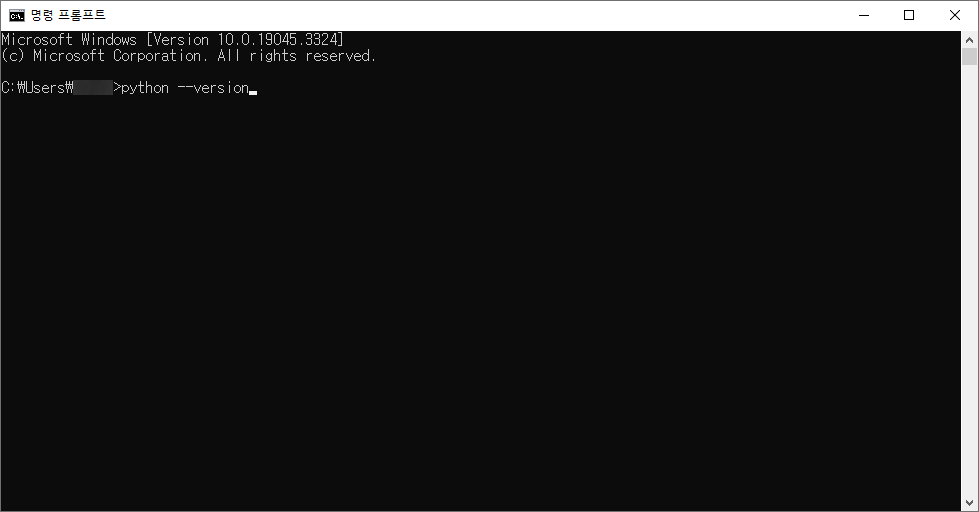
# 1. 작은 따옴표로 문자열을 감싸는 방법
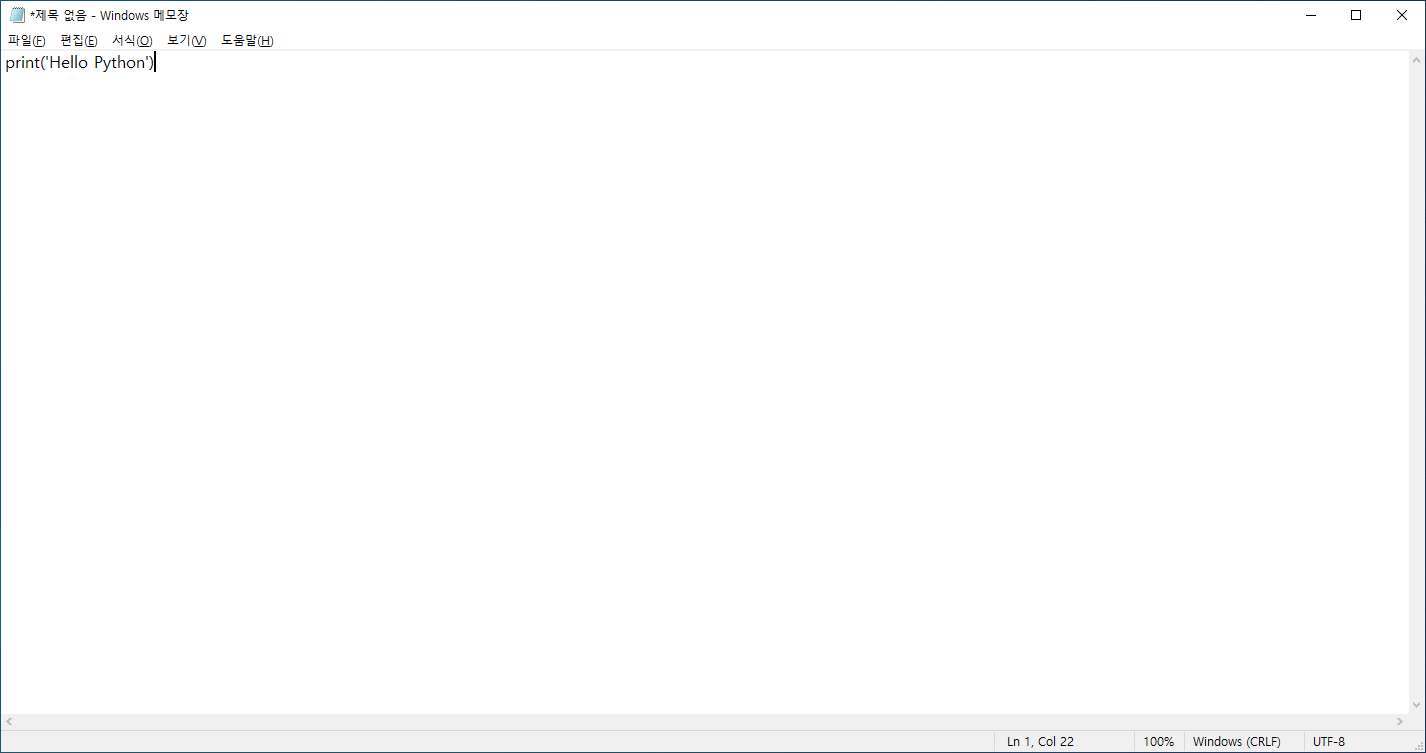
'Hello Python'
# 2. 큰 따옴표로 문자열을 감싸는 방법
"Hello Python"
# 3. 작은 따옴표 3개로 문자열을 감싸는 방법
'''Hello Python'''
# 4. 큰 따옴표 3개로 문자열을 감싸는 방법
"""Hello Python"""
위와 같은 방식들로 사용 가능합니다
작은/큰 따옴표 1개 안에 문자열 넣기, 작은/큰 따옴표 3개 안에 문자열 넣기, 총 4가지의 방법이 있는데 괜히 4가지의 방법이 있는것이 아니고 각각 용도에 맞게끔 사용하면 됩니다
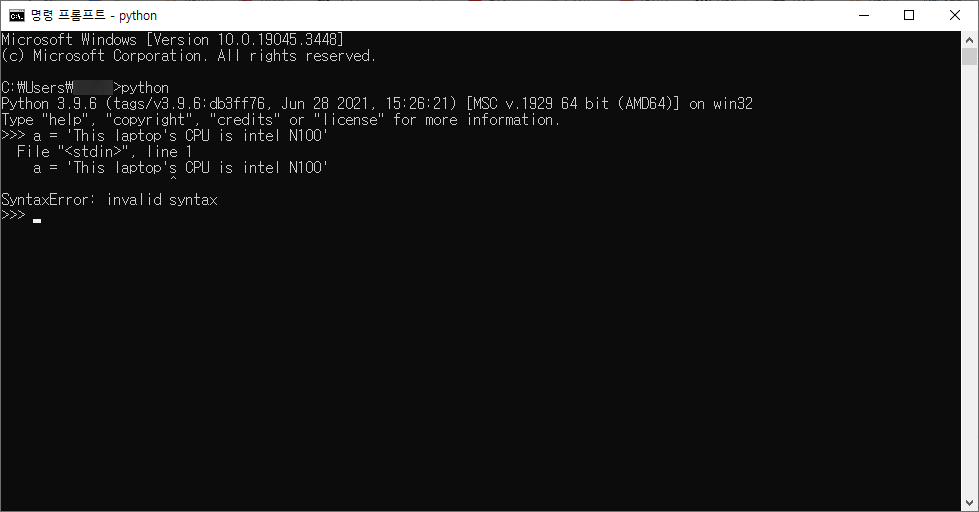
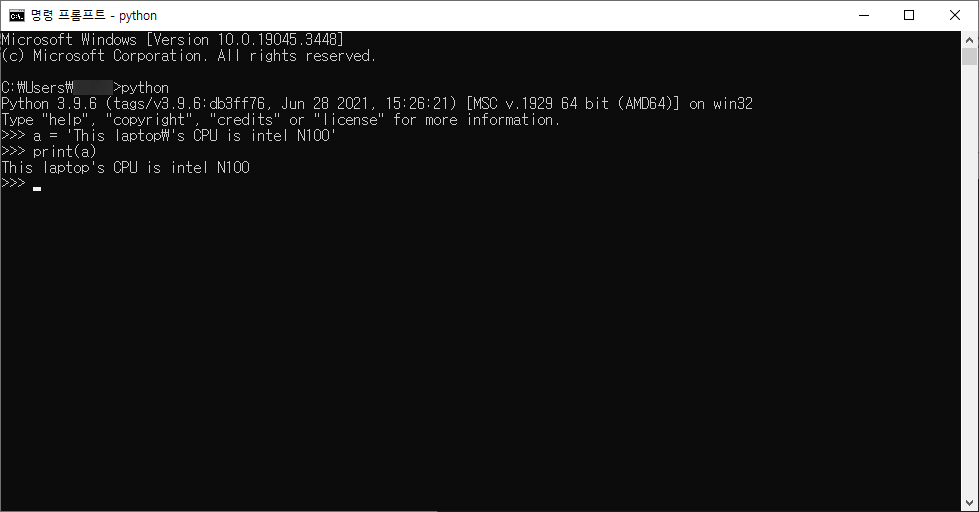
만약에 입력하는 문자열 중간에 같은 따옴표('를 썼으면 ' 또는 "를 썼으면 ") 가 들어가 있다면 어떻게 될까요?
a = 'This laptop's CPU is intel N100'
입력 문자열 중간에 작은 따옴표가 들어가있고 이것을 입/출력해보도록 하겠습니다
과연 아무런 문제 없이 입/출력이 될까요?
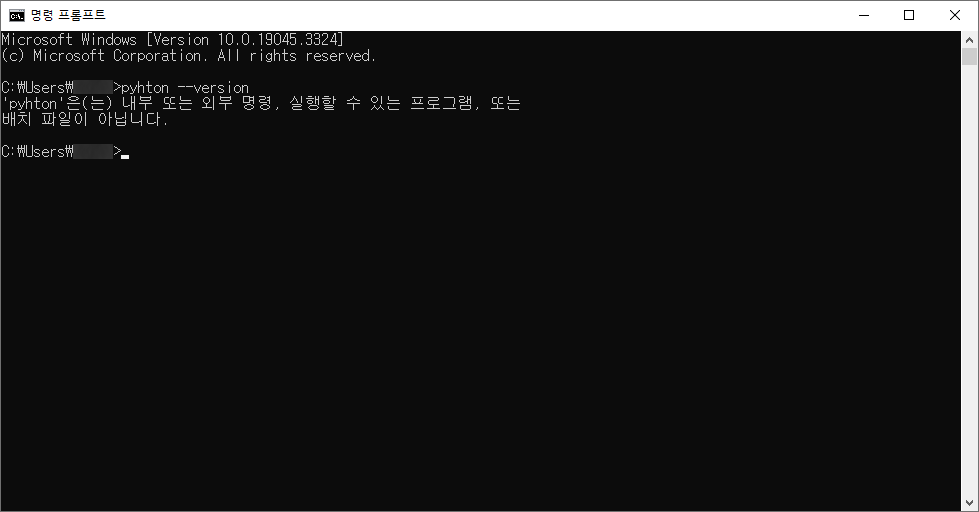
SyntaxError: invalid syntax 라는 오류가 나오면서 입력조차도 안됩니다
잘 쓴거 같은데 왜 안될까요?
문자열을 작은 따옴표로 감싸준 다음에 중간에 작은 따옴표가 들어가서 파이썬은 중간에 문장이 끊긴것으로 인식합니다
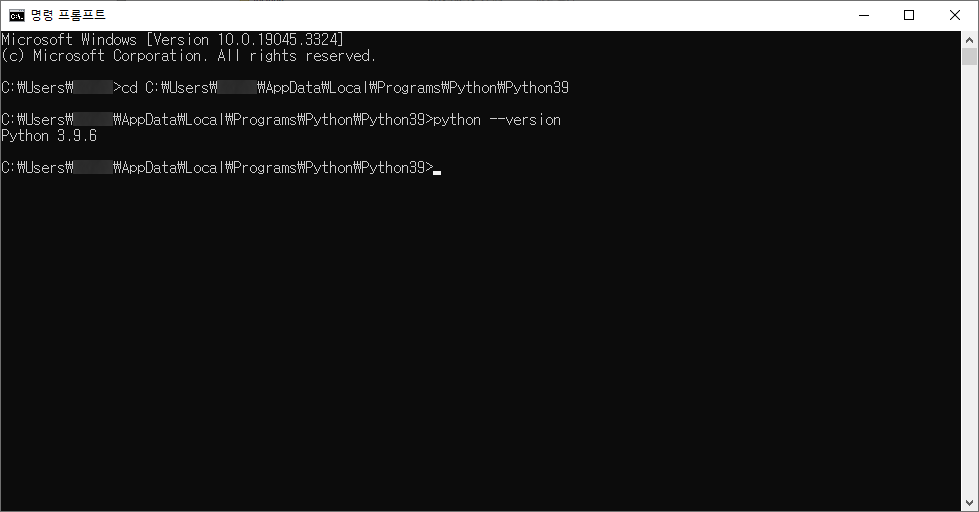
따라서 필자가 위에서 작성한 코드를 실제로 파이썬은 이런식으로 인식합니다
a = 'This laptop'
이미 다 입력해놨는데 뒤에 알 수 없는 추가적인 문자열들이 있으니 오류가 발생하는 것입니다
이 문제를 해결할 방법이 몇가지가 있는데 그 중 4가지 소개하도록 하겠습니다
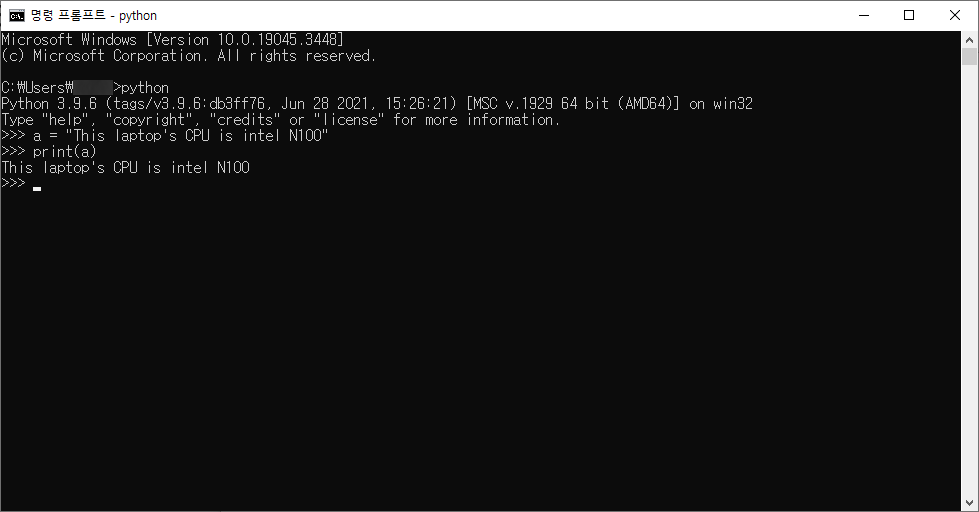
# 1. 큰 따옴표로 문자열을 감싸는 방법
a = "This laptop's CPU is intel N100"
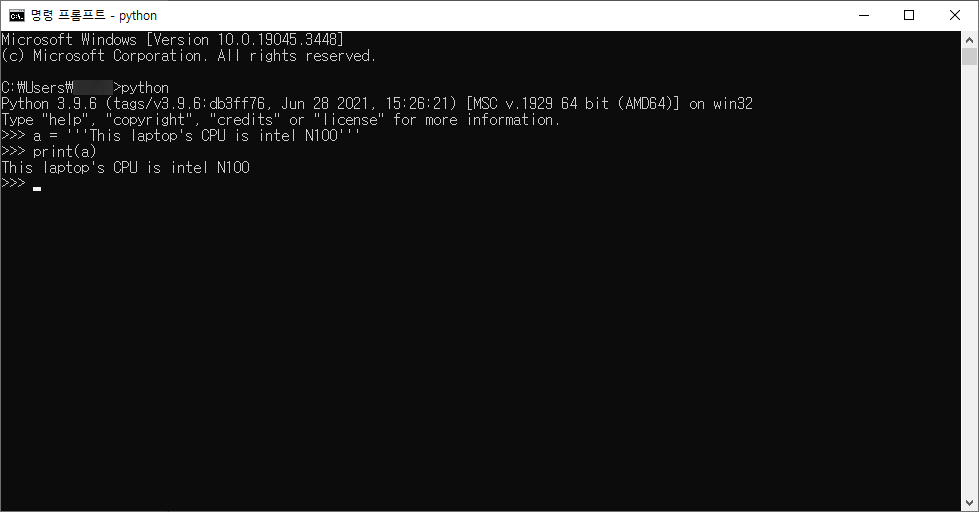
# 2. 작은 따옴표 3개로 문자열을 감싸는 방법
a = '''This laptop's CPU is intel N100'''
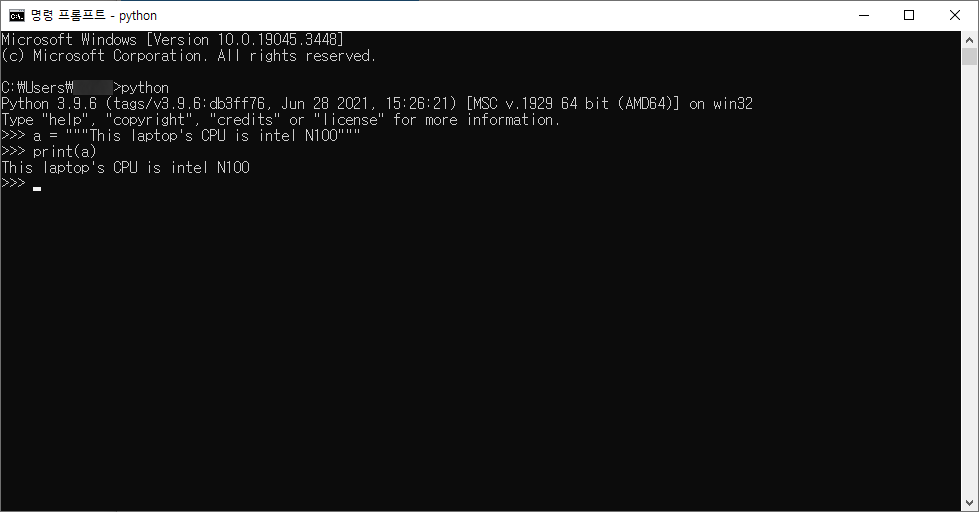
# 3. 큰 따옴표 3개로 문자열을 감싸는 방법
a = """This laptop's CPU is intel N100"""
# 4. 역슬래시(\) 를 사용하는 방법
a = 'This laptop\'s CPU is intel N100'
4가지 방법 모두 잘 됩니다
어느것을 사용해도 되지만 개인적으로는 4번 방법을 가장 많이 사용합니다
대단한 이유는 없고 1~3번 방법은 큰 따옴표를 입력할 때 Shift + 따옴표 기호를 입력, 따옴표 기호를 3개 입력해야 하는 번거로움이 있지만
4번 방법은 중간에 역슬래시(\) 만 추가해주면 되기 때문입니다
따옴표를 구분해서 사용하면 아래와 같은 문장을 출력할 때 도움이 됩니다
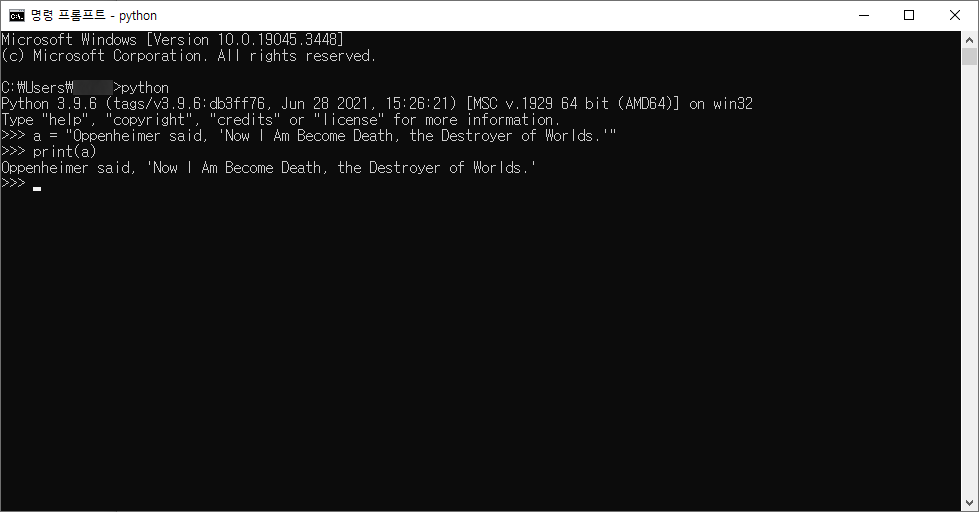
# Oppenheimer said, 'Now I Am Become Death, the Destroyer of Worlds.' 출력하기
a = "Oppenheimer said, 'Now I Am Become Death, the Destroyer of Worlds.'"
print(a)
따옴표를 구분해서 사용하면 아래와 같은 문장을 출력할 때 도움이 됩니다
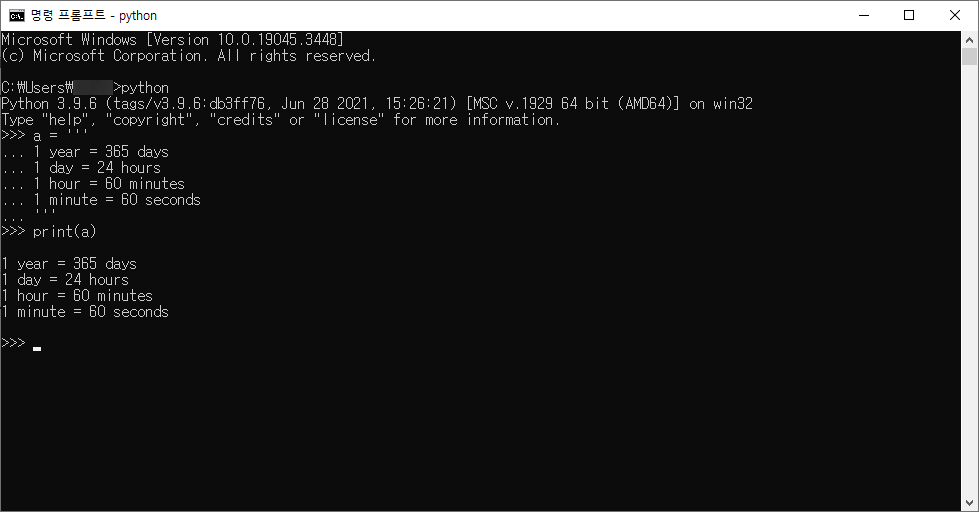
a = '''
1 year = 365 days
1 day = 24 hours
1 hour = 60 minutes
1 minute = 60 seconds
'''
print(a)
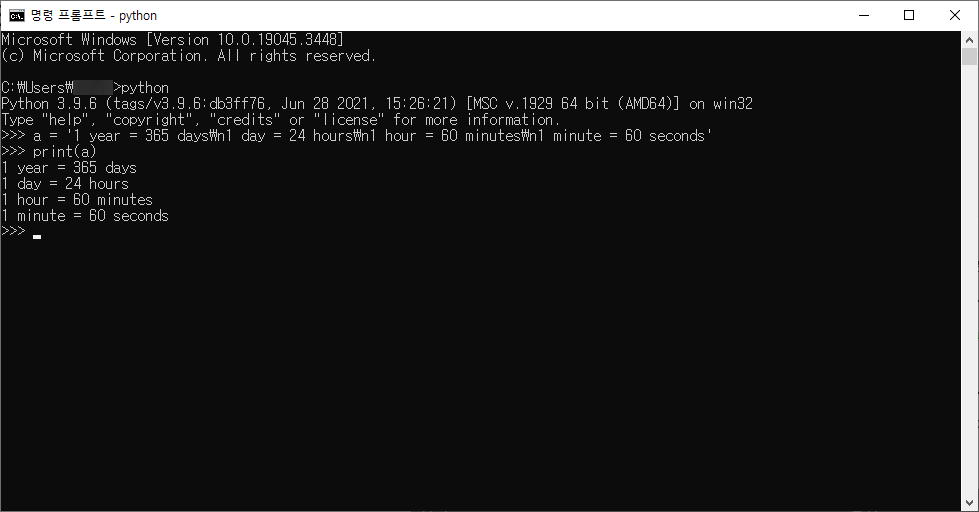
여러줄의 문자를 출력하는 방법에는 따옴표를 3개 사용하는 방법 말고 \n(줄 바꿈) 을 사용해도 됩니다
a = '1 year = 365 days\n1 day = 24 hours\n1 hour = 60 minutes\n1 minute = 60 seconds'
print(a)
다만 위의 코드처럼 줄 바꿈을 하지 않은채로 코드를 작성하면 가독성이 매우 떨어지기 때문에 별로 추천하는 방법은 아니고 이런식으로도 작성할 수 있구나 하고 넘어가면 됩니다
이스케이프(Escape) 문자(또는 이스케이프 코드) 이며 이스케이프 문자는 아래와 같습니다
항목
설명
\n
문자열 안에서 줄 바꿀 때 사용
\t
문자열 안에서 탭 간격을 맞출 때 사용
\\
역슬래시(\) 를 출력할 때 사용
\'
작은 따옴표(') 를 출력할 때 사용
\"
큰 따옴표(") 를 출력할 때 사용
위의 5종류 외에도 더 있기는 하지만 그 외에는 많이 사용하지 않기 때문에 넣지 않았습니다
문자열도 연산이 가능은 합니다
다만 더하고 곱하는 기능만 가능합니다
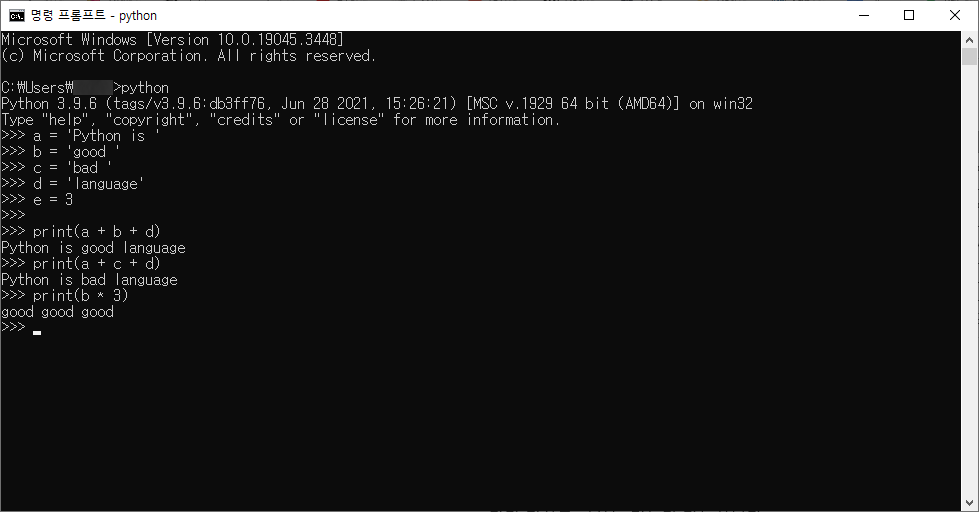
a = 'Python is '
b = 'good '
c = 'bad '
d = 'language'
e = 3
print(a + b + d)
print(a + c + d)
print(b * 3)
문자열에 문자열을 더하면 이어 쓰기가 되고
문자열에 숫자를 곱하면 해당 문자열을 곱한 숫자만큼 반복하게 됩니다
문자열의 길이를 구할때는 len() 을 사용합니다
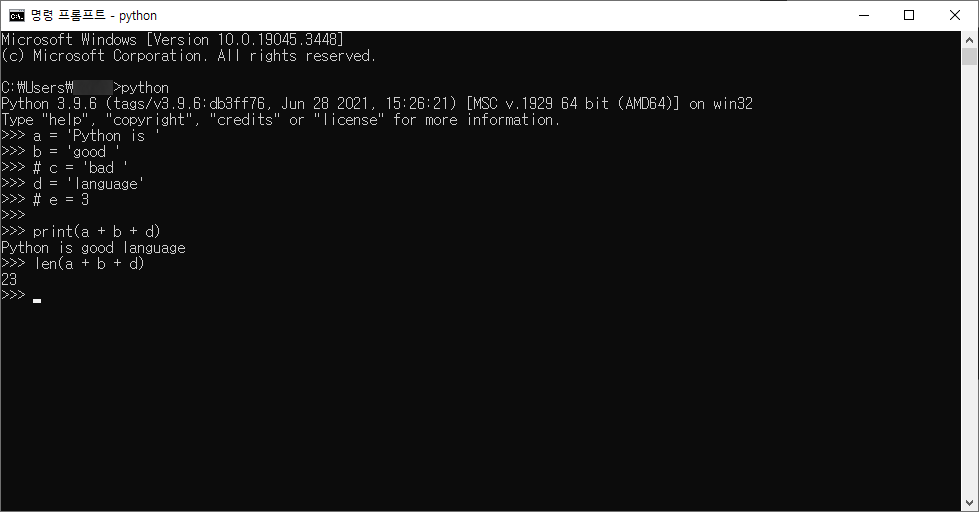
위의 예제를 조금만 수정해보겠습니다
a = 'Python is '
b = 'good '
# c = 'bad '
d = 'language'
# e = 3
print(a + b + d)
len(a + b + d)
길이가 23, 즉 23자의 글자가 있다는 뜻이고 이는 띄어쓰기(Space) 를 포함한 값입니다
어디서부터 해야할지 모르거나 고성능 컴퓨터가 없더라도 로라 만드는 방법을 알려드릴 수 있습니다!
이 가이드에서는 제 깃헙(GitHub) 페이지의 리소스를 사용하겠습니다. 스테이블 디퓨전을 처음 사용하는 경우 이미지를 직접 생성하고 유용한 도구를 배울 수 있는 전체 가이드도 준비되어 있습니다.
제 취미와 그 취미에 쏟는 노력을 공유하는 기쁨을 위해 이 가이드를 만들고 있습니다. 필자는 이미지 생성 소프트웨어를 포함한 모든 정보가 모든 사람에게 무료로 제공되어야 한다고 생각합니다. 하지만 AI를 이용해 사람들을 속이거나 사기를 치거나 불법 행위를 하는 것을 지지하지 않습니다. 저는 그냥 재미로 하는 것입니다.
인내심 새로운 개념을 쉽게 설명하도록 노력하겠습니다. 주의 깊게 읽고 비판적 사고를 사용해 문제가 생기더라도 포기하지 마십시오.
LoRA 만들기
어렵기로 소문나 있습니다. 옵션이 너무 많고 어떤 기능을 하는지 설명하는 글도 없으니까요. 이 글은 누구나 1시간 이내에 아무것도 모르는 상태에서 나만의 LoRA를 만들 수 있도록 과정을 간소화 했습니다. 나중에 사용할 수 있는 몇가지 고급 설정은 그대로 유지하면서요.
물론 6GB 이상의 VRAM이 있는 엔비디아 그래픽카드가 있다면 독자의 컴퓨터에서 LoRA를 학습시킬 수 있습니다. 그러나 이 가이드에서는 그렇게 하지 않고 구글의 고성능 컴퓨터와 그래픽카드를 하루에 몇시간(몇몇은 주당 20시간이라 함) 대여할 수 있는 구글 코랩(Google Colab) 을 사용해보겠습니다. 10달러를 결제하면 최대 50시간까지 추가로 이용할 수 있지만 필수 사항은 아닙니다. 또한 구글 드라이브의 저장 용량도 약간 사용하게 됩니다.
이 글은 애니메이션 위주로 설명하지만 실사 사진에도 적용됩니다. 하지만 실제 사람의 얼굴을 무단으로 사용하는 경우에는 도움을 드리지 않습니다.
LoRA의 종류
아시는것처럼 LoRA는 아래의 용도로 학습, 사용할 수 있습니다.
캐릭터나 인물
스타일
자세나 컨셉
그 외
하지만 지금은 다양한 종류의 LoRA가 있습니다.
LoRA: 고전적입니다. 아무 문제 없이 WEBUI에서 사용할 수 있습니다.
LoCon: 더 많은 학습 레이어가 있으며 그림체에 좋은 것으로 알려졌습니다. WEBUI에서 일반 LoRA처럼 사용하려면 Lycoris 확장 프로그램이 필요합니다.
LoHa: 더 많은 학습 레이어와 새로운 수학적 알고리즘이 있습니다. 학습하는데 훨씬 오랜 시간이 걸리지만 스타일과 캐릭터와 같은 복잡한 것을 동시에 학습할 수 있습니다. 필자는 추천하지 않습니다. 일반 LoRA처럼 사용하려면 WEBUI에 Lycoris 확장 프로그램이 필요합니다.
1단계: 데이터셋 만들기
이것은 LoRA를 만드는데 있어서 가장 길고 중요한 부분입니다. 데이터셋은 이미지와 그 설명의 모음으로 각 쌍은 동일한 파일 이름(1.png, 1.txt) 을 가지며, 모두 AI가 학습하기를 원하는 공통점을 갖고 있습니다. 데이터셋의 품질은 중요합니다. 이미지에는 자세, 각도, 배경, 옷 등의 예시가 2개 이상 있어야 합니다. 예를 들어서 모든 이미지가 얼굴 근접샷이면 몇가지 예시를 추가하지 않으면 LoRA가 전신샷을 생성하는데 어려울 수도 있습니다(생성하는것이 가능은 합니다). 더 다양한 이미지를 추가하려면 개념을 더 잘 이해할 수 있으므로 AI가 학습 데이터에 없던 새로운 것을 생성해 낼 수 있습니다. 예를 들어서 새로운 자세와 다른 옷을 입은 캐릭터가 나올 수 있습니다. 최소 5개의 이미지로 평범한 LoRA를 학습시킬 수 있지만 20개 이상, 최대 1,000개 까지 사용하는 것을 권장합니다.
일반적인 이미지의 경우 "full body photograph of a woman with blonde hair sitting on a chair" 와 같이 짧고 자세한 문장이 필요합니다. 애니메이션의 경우 booru 태그(1girl, blonde hair, full body, on chair, 그 외) 를 사용해야 합니다. 데이터셋에서 태그가 어떻게 작동하는지 보겠습니다. LoRA는 학습에 사용하는 기본 모델을 사용하여 무슨 일이 일어나고 있는지 참조하므로 상세하게 알려줘야 합니다. 태그에 포함하지 않은것들은 모두 LoRA의 일부가 됩니다. LoRA는 얼굴이나 액세서리 등 말로 쉽게 설명할 수 없는 디테일을 흡수하기 때문입니다. 이 사실을 알면 모든 텍스트 파일의 시작 부분에 있는 고유한 단어나 문구인 활성화 태그(activation tag) 에 이러한 세부 정보를 포함시켜 LoRA가 쉽게 메시지를 표시하도록 할 수 있습니다.
온라인에서 이미지를 수집하고 수동으로 설명할 수 있습니다. 다행히도 새로운 데이터셋 제조기 코랩을 사용하면 이 과정의 대부분을 자동으로 할 수 있습니다.
아래는 사용 방법입니다.
설정: 이 작업은 구글 드라이브에 연결됩니다. 프로젝트의 간단한 이름과 원하는 폴더를 선택한 다음 왼쪽에 있는 재생 버튼을 눌러 셀을 실행합니다. 권한을 묻는 창이 나오면 Google Drive에 연결 → 계정 선택 → 허용을 눌러줍니다.
학습할 이미지를 갖고 있다면 구글 드라이브에 Loras/[프로젝트_이름]/dataset 폴더에 이미지를 업로그 하면 3단계부터 하면 됩니다.
Gelbooru에서 이미지 모으기: 애니메이션의 경우 많은 짤들을 사용하여 LoRA를 학습시킵니다. Gelbooru는 이미지에 대한 모든 것을 설명하는 수천개의 booru 태그를 통해 이미지를 분류하며 나중에 이미지에 태그를 지정하는 방법입니다. 이 단계에서는 기본적으로 컨셉, 캐릭터, 스타일을 나타내는 특정 태그가 포함된 이미지를 요청하는 것이 좋습니다. 이 셀을 실행하면 결과가 표시되고 계속할 것인지 묻는 메시지가 표시됩니다. 결과가 마음에 들면 네(Yes) 라고 입력하고 이미지가 다운로드 될 때 까지 잠시 기다립니다.
이미지 선별 작업: Gelbooru에는 중복된 이미지가 많기 떄문에 FiftyOne AI를 사용해 중복된 이미지를 감지해서 삭제할 수 있도록 표시할겁니다. 이 셀은 실행하면 몇 분 정도 걸립니다. 하지만 아직 삭제되지 않고 셀 아래에 모든 이미지를 격자로 표시하는 대화형 영역이 나타납니다. 여기서 마음에 들지 않은 이미지를 선택하고 삭제하도록 표시할 수 있습니다. 품질이 낮거나 관련 없는 이미지가 있는 경우에는 삭제하는 것이 좋습니다. 모든 작업을 마쳤으면 대화형 영역 위의 텍스트 상자에 Enter 키를 눌러 변경 사항을 적용해줍니다.
이미지에 태그 달기:이미지를 설명하는 애니메이션 태그를 할당하는데는 WD 1.4 tagger AI를 사용하고 실사나 기타 이미지에 대한 캡션은 BLIP AI를 사용하면 됩니다. 이 작업은 몇 분 정도 소요됩니다. threshold 값을 0.35 ~ 0.5 정도로 설정하면 좋은 결과를 얻을 수 있습니다. 이 셀을 실행하면 데이터셋에서 가장 일반적인 태그가 표시되며 다음 단게에서 유용하게 사용할 수 있습니다.
태그 선별: 이 과정은 애니메이션 태그에 대해서 매우 유용합니다. 여기에서는 LoRA에 대한 activation tag(또는 트리거 워드, trigger word) 을 지정할 수 있습니다. 스타일을 학습하는 경우 LoRA가 항상 활성화 되도록 activation tag가 필요하지 않을수도 있습니다. 캐럭터를 학습하는 경우 신체의 특징이나 머리카락, 눈 색깔과 같이 캐릭터의 고유한 공통 태그를 삭제(가지치기) 하는 경향이 있습니다. 이렇게 하면 activation tag에 흡수됩니다. 이 과정을 하면 LoRA의 프롬프트를 사용하는 것이 더 쉽지만 유연성은 떨어집니다. 몇몇 사람들은 캐릭터 의상을 정의하는 단일 태그를 갖기 위해 모든 의상을 가지치기하는 경향이 있습니다. 과도한 가지치기는 일부 디테일에 영향을 미치므로 권장하지 않습니다. 보다 유연한 접근 방식은 'striped shirt, vertical stripes, vertical-striped shirt' 와 같은 중복이 있는 태그를 모두 'striped shirt' 태그로 병합하는 것입니다. 이 단계는 원하는 만큼 여러번 실행할 수 있습니다.
준비: 데이터셋은 구글 드라이브에 저장됩니다. 이 데이터셋으로 원하는 모든 작업을 할 수 있지만 이 글의 다음 단계로 이동하여 LoRA 학습을 시작해 보도록 하겠습니다!
2단계: 설정과 학습
이 부분이 까다롭습니다. LoRA를 학습시키기 위해 제 LoRA 학습 코랩을 사용하겠습니다. 필요한 모든 설정이 포함된 단일 셀로 구성되어 있습니다. 이런 설정 중 대부분은 변경할 필요가 없습니다. 하지만 이 글에 있는 코랩에서 각 설정이 어떤 기능을 하는지 설명해 드리니 나중에 이 설정들로 활용할 수 있습니다.
설정은 아래와 같습니다.
Setup: 1단계에서 사용한 것과 동일한 프로젝트 이름을 이름을 입력하면 자동으로 적용됩니다. 여기에서 학습을 위한 기본 모델을 변경할 수 있습니다. 기본 모델은 2가지가 권장되지만 원하는 경우 사용자가 직접 다운로드 링크를 추가해서 사용할 수 있습니다. 데이터셋 생성시 사용할 때 지정한 폴더 경로를 동일하게 사용하면 됩니다.
Processing: 데이터셋의 처리 방식을 변경하는 설정은 아래와 같습니다.
해상도는 512로 설정해야 하며 이는 스테이블 디퓨전의 기본값입니다. 해상도를 높이면 학습 속도가 훨씬 느려지지만 정밀한 디테일을 표현하는데 도움됩니다.
flip_aug는 더 많은 이미지가 있는 것처럼 더 고르게 학습시키는 트릭이지만 AI가 좌우를 헷갈리게 만들 수 있으므로 사용자가 선택해야 합니다. 번역자의 추가 설명: 캐릭터를 학습시키는 경우 좌우 대칭이 아닌 경우(머리 한 쪽에만 장식이 있는 경우 등) 에는 해당 설정을 사용하지 말아야 합니다.
애니메이션 태그를 사용하는 경우 shuffle_tags를 활성화 해둬야지 프롬프트가 더 유연해지고 편향성을 줄일 수 있습니다.
활성화 태그(activation_tags) 는 중요하므로 이 글의 데이터셋 부분에서 추가한 경우 1로 설정하세요. 이것을 keep_tokens라고도 합니다.
Steps: 여기에서 주의해야 할 점이 있습니다. 이미지 수, 반복 횟수(repeats), 에폭 수(epochs), 배치 크기(batch size) 등 4가지 변수가 작용합니다. 이런 변수에 따라 총 단계가 결정됩니다.
총 에폭 또는 최종 단계를 설정하도록 선택할 수 있으며 아래에서 몇 가지 예시를 보겠습니다. 단계가 너무 적으면 LoRA가 덜 학습되어서 쓸모 없고 단계가 너무 많으면 이미지가 왜곡됩니다. 그렇기 때문에 LoRA를 에폭마다 저장하여 나중에 비교하고 결정할 수 있도록 합니다. 따라서 반복 횟수를 줄이고 에폭 값을 늘리는 것이 좋습니다.
LoRA를 학습시키는 방법에는 여러가지가 있습니다. 필자 개인적으로 하는 방법은 빠르게 학습할지, 천천히 학습할지 여부에 따라 10~20개의 에폭 중에서 선택할 수 있도록 에폭의 균형을 맞추는데 중점을 둡니다. 또한 일반적으로 이미지가 많을수록 안정화 단계가 더 많이 필요하다는 것을 알게 되었습니다. 새로운 min_snr_gamma 옵션 덕분에 LoRA를 학습시키는데 걸리는 에폭이 줄어들었습니다. 아래는 시도해 볼 수 있는 몇 가지 설정들입니다.
20 이미지 * 10 반복 횟수 / 2 배치 크기 = 1,000 학습
100 이미지 * 3 반복 횟수 / 2 배치 크기 = 1,500 학습
400 이미지 * 1 반복 횟수 / 2 배치 크기 = 2,000 학습
1,000 이미지 * 1 반복 횟수 / 3 배치 크기 = 3,300 학습
Learning: 가장 중요한 설정입니다. 하지만 이 중 어떤 것도 처음부터 변경할 필요는 없습니다.
unet learning rate는 LoRA가 정보를 얼마나 빨리 흡수하는지를 결정합니다. 스텝 수와 마찬가지로 너무 적으면 LoRA는 아무것도 하지 않고 너무 크면 생성하는 모든 이미지가 왜곡됩니다. 특히 프롬프트에서 LoRA의 가중치를 변경할 수 있기 때문에 작업 값에 유연한 범위가 있습니다. dim 값을 8~32 사이로 설정한다 가정하면(아래 참조 바람) 거의 모든 상황에서 unet learning rate는 5e-4를 권장합니다. 천천히 학습시키고 싶다면 1e-4, 2e-4가 더 좋을겁니다.
text encoder learning rate은 특히 스타일에서 덜 중요합니다. 태그를 더 잘 학습하는데 도움이 되지만 태그가 없어도 학습이 되기 떄문입니다. 일반적으로 unet learning rate의 1/2 또는 1/5이어야 하고 권장 값은 1e-4, 5e-5입니다.
scheduler는 시간이 지남에 따라 학습 속도를 조절해 줍니다. 이것이 중요하지는 않지만 도움이 됩니다. 필자는 항상 cosine with 3 restarts을 사용하는데 개인적으로 LoRA를 잘 학습시키는것 같습니다. cosine, constant, and constant with warmup들도 한번 사용해보세요. 이들이 잘못되는 일은 없습니다. 또한 warmup ratio는 학습을 효율적으로 시작하는데 도움이 되며 기본값인 5%가 잘 작동합니다.
Structure: 앞서 설명한 3가지 LoRA 중 원하는 LoRA 유형을 선택하면 됩니다. 개인적으로 캐릭터는 LoRA를, 스타일은 LoCon을 사용하는 것을 추천합니다. LoHa는 학습하기에 어렵습니다.
dim/alpha는 LoRA의 용량과 스케일링을 의미하며 논란의 여지가 있습니다. 몇 달 동안은 모두가 각각 128이 가장 좋다고 서로에게 알렸는데 그 이유는 이 설정이 디테일이 가장 좋았다는 실험 결과 때문입니다. 그러나 당시에는 dim/alpha를 낮추면 학습률을 높여야 동일한 수준의 디테일을 구현할 수 있다는 사실이 알려지지 않았기 때문에 이런 실험에는 문제가 많았습니다. 이 LoRA 학습 설정은 144MB로 나오기에 안타깝습니다. 필자는 개인적으로 캐릭터에 적합한 설정이고 용량이 18MB 밖에 안되는 16/8을 사용합니다. 현재 권장되는 값은 아래와 같습니다(더 많은 실험 환영).
Ready: 이제 LoRA를 학습시킬 이 셀을 실행할 준비가 되었습니다. 사전 준비 작업에는 5분 정도가 걸리고 그 이후로 학습 단계를 합니다. 시간은 1시간이 걸리지 않으며 결과물은 구글 드라이브에 저장됩니다.
3단계: 테스트
LoRA 학습을 완료한 뒤에도 테스트해서 제대로 작동하는지를 확인해야 합니다. 구글 드라이브의 /lora_training/outputs/ 폴더로 이동해서 [프로젝트_이름] 폴더 안에 있는 모든 파일들을 다운로드 하세요. 이 파일들은 각각 학습의 다른 시점에 저장된 다른 LoRA들입니다. 각각 01, 02, 03 등과 같은 숫자가 있습니다.
다음은 LoRA를 사용하는 최적의 방법을 찾기 위한 간단한 워크플로입니다.
마지막 LoRA에 0.7~1.0의 가중치로 프롬프트에 입력하고 가이드의 태그 지정 부분에서 본 가장 일반적인 태그 중 일부를 포함하세요. 학습하려고 했던 것과 비슷하거나 유사한 것을 볼 수 있을겁니다. 만족하거나 더 이상 개선할 수 없을 때 까지 프롬프트를 조정하세요.
X/Y/Z 플롯(plot) 을 사용해 서로 다른 에폭을 비교합니다. 이것은 WEBUI의 기본 기능입니다. 아래로 이동해서 Script에서 X/Y/Z plot를 선택하세요. 프롬프트에 첫 번째 에폭의 LoRA를 입력하고 (예를 들어서 <lora:projectname-01:0.7>) 스크립트의 X 값에 '-01, -02, -03 등'을 입력합니다. X 값이 Prompt S/R인지 확인하십시오. 이렇게 하면 프롬프트에서 교체가 수행되어 LoRA의 다른 숫자를 통과하므로 품질을 비교할 수 있습니다. 시간을 절약하려면 먼저 2번째 또는 5번째 마다 비교할 수 있습니다. 보다 공정하게 비교하려면 이미지를 일괄 처리하는 것이 이상적입니다.
마음에 드는 에폭을 찾았다면 최적의 가중치를 찾아보세요. 이번에는 '0.5>, 0.6>, 0.7>, 0.8>, 0.9>, 1>' 과 같은 X값을 사용해서 X/Y/Z 플롯을 다시 실행합니다. 이렇게 하면 다른 LoRA 가중치로 변경하라는 프롬프트의 일부를 대체할 수 있습니다. 다시 말하지만 일괄적으로 비교하는 것이 좋습니다. 이미지를 왜곡하지 않으면서 최상의 디테일을 구현하는 가중치를 찾고 있습니다. 원하는 경우 2단계와 3단계를 X/Y로 동시에 돌리면 시간이 더 오래 걸리지만 더 확실하게 작업할 수 있습니다.
마음에 드는 결과물을 찾았다면 축하합니다! 다양한 상황, 방향, 옷 등을 계속 테스트해서 LoRA가 학습 데이터에 없는 창의적인 작업을 할 수 있는지 확인하세요.
마지막으로 잘못되었을 수도 있는 몇 가지 사항들을 알려드립니다.
LoRA가 아무것도 하지 않거나 아주 조금만 작동하는 경우에는 학습률을 낮게 설정했거나 더 오래 학습해야 하는 과소적합 상태일 수도 있습니다. 프롬프트 입력에서 실수한 부분은 없는지 확인해보세요.
LoRA가 작동은 하지만 원하는 것과 비슷하지 않다면 마찬가지로 충분히 학습되지 않았거나 데이터셋(이미지와 태그) 의 품질이 낮기 때문일 수도 있습니다. 일부 컨셉은 학습하기 훨씬 더 어렵기 때문에 방법을 잘 모르는 경우에는 커뮤니티의 도움을 받는것이 좋습니다.
LoRA가 왜곡된 이미지나 아티팩트를 생성하고, 이전 에폭이 도움이 되지 않거나, NaN 오류가 발생하는 경우에는 학습률이나 반복 횟수가 너무 높아서 생기는 과대적합입니다.
LoRA가 수행하는 작업이 너무 제한되어 있다면 이를 오버핏이라 합니다. 데이터셋이 너무 적거나 태그가 제대로 지정되지 않았거나 약간 과대적합 되었을 수도 있습니다.
스테이블 디퓨전은 PC에서 실행할 수 있는 아주 강력한 AI 이미지 생성 소프트웨어입니다. AI의 두뇌와 같은 기능을 하는 '모델'을 사용하며, 누군가가 학습시킨다면 거의 모든것을 만들 수 있습니다. 많이 사용되는 분야는 애니메이션 아트, 포토리얼리즘, 야짤입니다.
독자가 만든 이미지는 사용된 모델의 라이선스에 따라 어떤 용도로든 사용할 수 있습니다. 법적 의미에서 '귀하의 것'인지 여부는 현지 법률에 따라 다르며 종종 결정적이지 않습니다. 필자, 스테이블 디퓨전, 스테이블 디퓨전 모델에 관련된 그 누구도 독자가 만드는 모든 것에 대해 책임을 지지 않으며 필자는 불법적이거나 유해한 콘텐츠를 만드는 것이 명시적으로 금지되어 있습니다.
이 가이드는 2023년 03월 현재 모범 사례에 대한 최신 정보를 담고 있습니다. AI에서의 일주일은 현실에서의 1년과 같으므로 이 가이드를 읽으실 떄 쯤에도 여전히 유용하길 바랍니다.
구글 코랩
스테이블 디퓨전을 사용하는 가장 쉬운 방법은 구글 코랩(Google Colab) 을 이용하는 것입니다. 구글의 컴퓨터를 빌려서 AI를 사용하는데 보통 매일 몇 시간의 시간 제한이 있습니다. 1개 이상의 구글 계정이 필요하며 설정과 결과 이미지를 저장하기 위해 구글 드라이브를 사용합니다.
상단에 있는 드라이브에 복사를 클릭합니다. 새 창이 열릴 때 까지 기다렸다가 새 창이 열리면 이천 창을 닫습니다. 설정을 저장할 수 있는 여러분만의 코랩이 만들어졌고 이제부터는 구글 드라이브에서 코랩을 열어야 합니다. 원본이 업데이트를 받으면 이 방법대로 해서 독자의 코랩을 교체해야 합니다.
구성에서 다음의 옵션들을 활성화 합니다: output_to_drive, configs_in_drive, no_custom_theme 다 했으면 Models, VAEs 부분에서 anything_vae, wd_vae, sd_vae 중 하나를 활성화 합니다
이미 안정적인 배포에 익숙한 경우 custom_urls 텍스트 상자에 원하는 리소스에 대한 링크를 붙여놓을 수 있습니다. 이 가이드의 뒷부분에 몇 가지 링크를 추가할 예정입니다. 링크는 각 파일에 대해 직접 다운로드(civitai, huggingface 추천) 해야하며 쉼표로 구분해야 합니다.
페이지의 첫 번째 코드 블록에서 시작이라고 표시된 곳의 왼쪽에 있는 재생 버튼(▶)을 누릅니다. 완료될 때 까지 몇분 정도 기다리면 하단에 몇 가지 진행률 메시지가 표시됩니다. 그러면 공개 링크가 생성되며 이 링크를 열어 스테이블 디퓨전을 시작할 수 있습니다. 코랩 탭을 계속 열어두세요! (모바일에서는 코랩 하단에 있는 트릭을 사용해 탭을 계속 열어두십시오)
기본으로 제공되는 Anything 4.5 모델 덕분에 괜찮은 애니메이션 이미지를 만들 수 있습니다. 하지만 우리는 더 많은 것들을 할 수 있습니다. 이 모든 옵션은 무엇일까요? 시작하려면 아래로 내리면 됩니다.
로컬 학습
PC에서 스테이블 디퓨전을 실행하려면 16GB 이상의 RAM, 4GB 이상의 VRAM(권장 8GB) 이 필요합니다. 이 글에서는 윈도우 10/11을 사용하고 엔비디아 그래픽카드 지포스 16, 지포스 20, 지포스 30을 사용하는 경우만 다루겠습니다(지포스 10도 가능). 죄송하게도 AMD, 리눅스, MacOS 사용자의 경우 사용하기가 더 어렵습니다. 하드웨어 요구 사항을 충족하지 않는 경우 위의 구글 코랩 방법으로 진행할 수 있습니다.
설치 파일을 실행하여 접근하기 쉬운 위치를 선택한 다음 설치가 완료될 때 까지 기다립니다.
프로그램을 실행합니다. 몇 가지 옵션이 보일건데 medvram와 xformers를 활성화 해줍니다. 12GB 이상의 VRAM이 있는 경우 medvram은 활성화 하지 않아도 됩니다.
추가 실행 옵션을 이렇게 설정해줍니다: --opt-channelslast --no-half-vae --theme dark (추가 옵션은 공백으로 구분합니다)
GPU가 6GB 이하의 VRAM이 있다면 --opt-split-attention-v1 을 추가 옵션으로 사용하면 VRAM 사용량을 더욱 줄일 수 있습니다.
컴퓨터에서 프로그램을 실행하되 휴대폰과 같은 다른 기기에서 사용하려면 --listen --enable-insecure-extension-access 을 추가 옵션을 사용하세요. 실행 후 동일한 Wi-Fi 네트워크 망에 있는 컴퓨터의 로컬 IP를 이용해 인터페이스에 접근합니다. --gradio-auth name:1234 을 사용해 비밀번호도 추가할 수 있습니다.
이 가이드에 있는 코랩을 사용하는 경우 파일의 다이렉트 다운로드 링크를 복사해 custom_urls라고 표시된 텍스트 상자에 붙여놓기 합니다. 여러개의 링크는 쉼표로 구분합니다.
로컬에서 프로그램을 실행하는 경우 모델은 일반적으로 stable-diffusion-webui/models/Stable-diffusion 폴더에 넣습니다.
확장자가 .safetensors인 체크포인트는 안전하지만 .ckpt는 바이러스가 있을수도 있으므로 주의하세요. 또한 모델을 선택할 때 fp16, fp32, pruned 중에서 선택할 수 있습니다. 모두 오차 범위 내에서 동일한 이미지를 생성하므로 용량이 가장 작은 파일(pruned-fp16) 을 선택하면 됩니다. 학습하거나 병합하려면 반대로 용량이 가장 큰 파일을 선택하세요.
팁: 새 파일을 수동으로 배치할 때마다 페이지 하단의 UI를 재시작하거나 드롭다운 옆에 있는 🔃버튼을 누르면 됩니다.
VAE
대부분의 체크포인트 파일에는 VAE가 내장되어 있지 않습니다. VAE는 '이미지를 사람이 볼 수 있는 형식으로 변환'해주는 작은 별도의 모델입니다. 이 기능이 없으면 색이 시퍼렇고 눈동자가 흐릿해지는 등의 문제가 발생합니다.
이 가이드에 있는 코랩을 사용하는 경우 실행하기 전에 선택하라고 말한것처럼 아래의 VAE가 있어야 합니다.
anything vae(orangemix vae로도 알려져 있음): 모든 애니메이션 모델에 사용합니다.
vae-ft-mse: 스테이블 디퓨전 자체의 최신 버전입니다. 실사 사진 모델 등에 사용됩니다.
kl-f8-anime2(와이푸 디퓨전Waifu Diffusion 으로도 알려져 있음): 더 오래되고 더 채도가 높은 결과를 생성합니다. Pastel Mix에서 사용합니다.
VAE 모델은 일반적으로 stable-diffusion-webui/models/VAE 폴더에 넣습니다.
이 가이드의 내용을 지금까지 따라하지 않았다면 설정 탭에서 스테이블 디퓨전 부분으로 가서 VAE를 선택해야 합니다.
팁: 새 파일을 수동으로 배치할 때마다 페이지 하단의 UI를 재시작하거나 드롭다운 옆에 있는 🔃버튼을 누르면 됩니다.
프롬프트
첫번째 탭인 txt2img에서 대부분의 이미지를 생성할겁니다. 여기에서 프롬프트(prompt)와 네거티브 프롬프트(negative prompt)를 볼 수 있을겁니다. 스테이블 디퓨전은 미드저니(Midjourney) 같은 인기있는 이미지 생성 소프트웨어와는 다르게 원하는 것을 그냥 물어볼 수 없습니다. 아주 구체적으로 써야 합니다. 대부분의 사람들은 잘 되는 프롬프트를 찾았고 다른 사람들이 추천하는 것들만 보는 경우가 있습니다. 프롬프트와 네거티브 프롬프트에 대한 필자의 예시를 보여드리겠습니다.
best quality, 4k, 8k, ultra highres, raw photo in hdr, sharp focus, intricate texture, skin imperfections, photograph of
EasyNegative, worst quality, low quality, normal quality, child, painting, drawing, sketch, cartoon, anime, render, 3d, blurry, deformed, disfigured, morbid, mutated, bad anatomy, bad art
EasyNegative: 위의 네거티브 프롬프트는 이미지를 개선하기 위해 여러가지 나쁜 내용을 인코딩하는 임베딩 또는 '매직 단어'인 EasyNegative를 사용합니다. 그렇지 않으면 아주 많은 네거티브 프롬프트를 써야 합니다.
이 가이드에 있는 코랩을 사용하고 있다면 이미 설치되어 있을겁니다. 다른것을 사용한다면 이 작은 파일을 다운로드 해서 stable-diffusion-webui/embeddings 폴더에 넣은 다음 WebUI 아래로 가서 UI 다시 시작을 눌러주세요. 그러면 해당 단어를 입력할 때 적용됩니다.
EasyNegative를 포함한 이러한 네거티브 프롬프트가 있는 경우와 없는 경우의 비교는 아래에서 확인할 수 있습니다.
위와 같은 '기본 프롬프트'가 표시된 후 원하는 내용을 입력하기 시작할 수 있습니다. 예로 young woman in a bikini in the beach, full body shot 가 있습니다. old, ugly, futanari, furry 등과 같이 싫어하는 다른 용어들을 네거티브 프롬프트에 자유롭게 추가할 수 있습니다.
생성(Generate) 버튼을 눌러 나중에 다시 사용할 수 있도록 프롬프트를 저장할 수 있습니다. 저장💾 버튼을 눌러 이름을 지정합니다. 나중에 스타일 드롭다운을 열어 선택한 다음 📋선택한 스타일을 현재 프롬프트에 적용할 수 있습니다.
프롬프트를 쓸 때 중요한 것 중 하나는 강조와 비강조 입니다. 괄호로 무언가를 둘러싸면 결과 이미지에서 해당 부분이 더 강조되거나 가중치가 부여되서 기본적으로 AI에게 해당 부분이 더 중요하다고 알려줍니다. 일반적으로 모든 단어의 가중치는 1이며 (소괄호) 한번마다 1.1이 곱해집니다(중복 사용 가능). 아니면 이런식으로 직접 가중치를 지정할 수도 있습니다: (full body:1.4). 비강조를 하려면 1이하로 설정하면 됩니다. [대괄호]는 가중치가 0.9이지만 더 낮추려면 여전히 소괄호를 써야합니다: (이런 식으로요:0.5)
또한 손과 발은 AI가 생성하기 어려운 것으로 유명합니다. 이런 방법을 사용하면 확률이 높아지지만 제대로 만드려면 포토샵, 인페이팅을 통해 수정하거나 컨트롤넷과 같은 고급 기술을 사용해야 할 수도 있습니다.
매개변수 생성
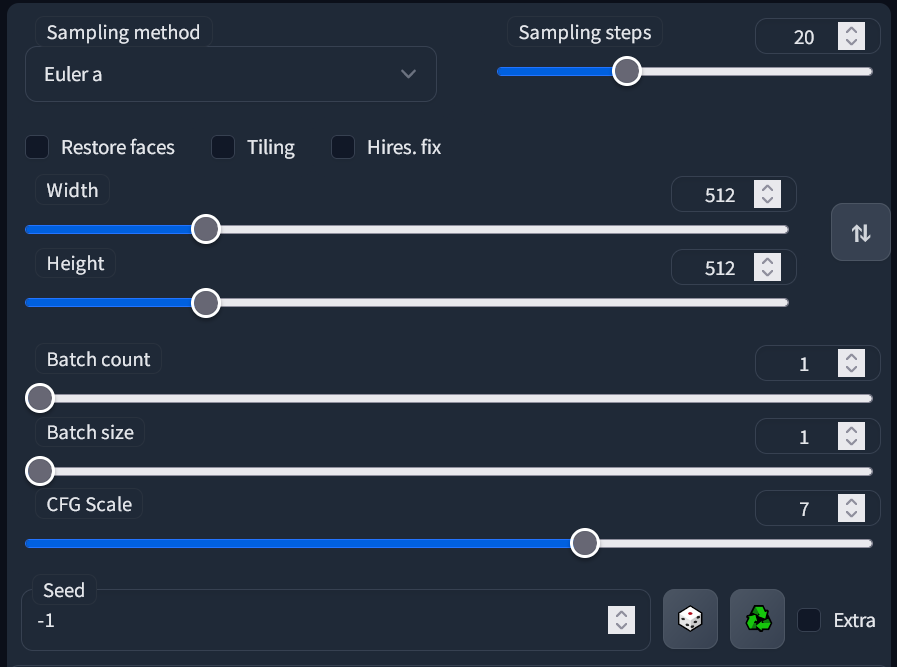
시작 페이지의 나머지 매개변수는 아래와 같이 표시됩니다.
샘플링 방법: 이미지를 공식화하는 알고리즘으로 각각 다른 결과를 보여줍니다. 기본값인 Euler a가 가장 좋은 경우가 많습니다. DPM++ 2M Karras, DPM++ SDE Karras의 결과도 좋습니다. 아래에서 비교를 확인해보세요.
샘플링 스텝: 샘플링 스텝은 미리 '계산'된 것이므로 단계가 많다 해서 항상 더 좋은 결과를 얻을 수 있는 것은 아닙니다. 필자는 30 스텝을 사용하지만, 20~50 스텝을 사용해도 일관되게 좋은 결과를 얻을 수 있습니다. 아래에서 비교를 확인해보세요.
너비와 높이: 512x512가 기본값이며 이미지가 왜곡되거나 변형될 수 있으므로 어느 값이던 768을 넘어서는 안됩니다. 더 큰 이미지를 만드려면 Hires fix를 확인하십시오.
배치 수와 배치 크기: 배치 크기는 GPU가 동시에 생성하는 이미지 수로 VRAM에 의해 제한됩니다. 배치 수는 해당 이미지를 반복할 횟수입니다. 배치에는 연속된 시드값이 있으며 시드값에 대한 자세한 내용은 아래에서 확인해보세요.
시드 값: 이미지 생성을 안내하는 숫자입니다. 동일한 프롬프트와 매개변수가 있는 동일한 시드 값은 작은 세부 사항과 일부를 제외하고는 매번 동일한 이미지를 생성합니다.
Hires fix: Lets you create larger images without distortion. Often used at 2x scale. When selected, more options appear:
Upscaler: The algorithm to upscale with. Latent and its variations produce creative and detailed results, but you may also like R-ESRGAN 4x+ and its anime version. More explanation and some comparisons further down ▼.
Hires steps: I recommend at least half as many as your sampling steps. Higher values aren't always better, and they take a long time, so be conservative here.
Denoising strength: The most important parameter. Near 0.0, no detail will be added to the image. Near 1.0, the image will be changed completely. I recommend something between 0.2 and 0.6 depending on the image, to add enough detail as the image gets larger, without destroying any original details you like.
Others:
Restore faces: May improve realistic faces. I never need it with the models and prompts listed in this guide as well as hires fix.
Tiling: Used to produce repeating textures to put on a grid. Not very useful.
Script: Lets you access useful features and extensions, such as X/Y/Z Plot ▼ which lets you compare images with varying parameters on a grid. Very powerful.
Here is a comparison of a few popular samplers and various sampling steps:
An explanation of the samplers used above: Euler is a basic sampler. DDIM is a faster version, while DPM++ 2M Karras is an improved version. Meanwhile we have Euler a or "ancestral" which produces more creative results, and DPM++ 2S a Karras which is also ancestral and thus similar. Finally DPM++ SDE Karras is the slowest and quite unique. There are many other samplers not shown here but most of them are related.
확장 기능
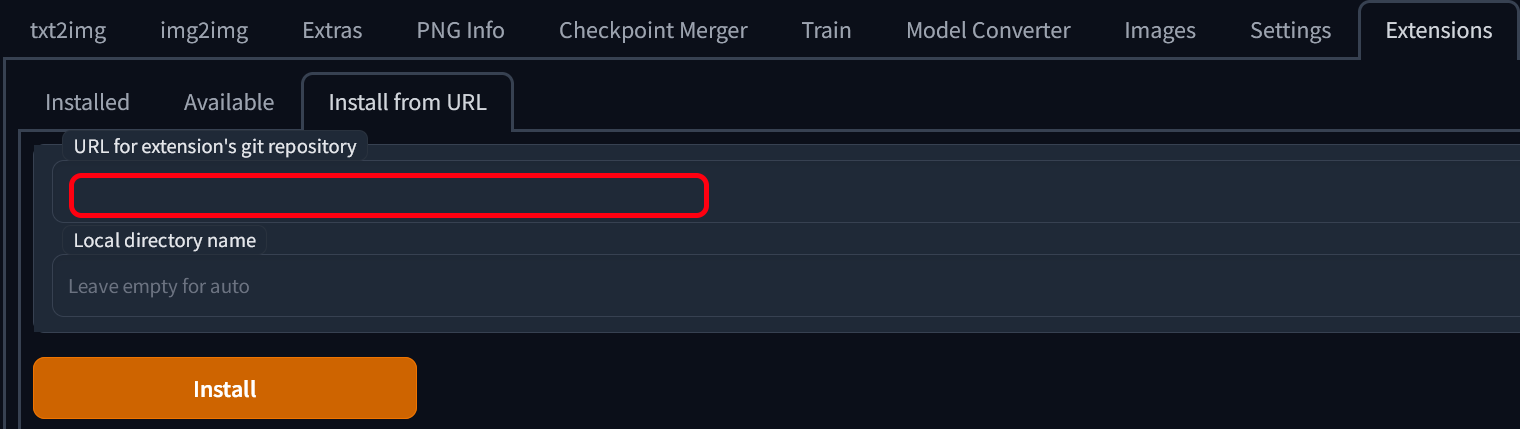
스테이블 디퓨전 WebUI는 확장 기능을 지원합니다. 확장(Extensions) 탭으로 이동한 다음 URL에서 설치(Install)로 이동해 여기에 있거나 다른곳에서 가져온 링크를 붙여넣기 해서 추가할 수 있습니다. 그런 다음 설치를 누르고 완료될 때 까지 기다립니다. 설치됨(Installed) 부분으로 이동해 적용(Apply) 를 누르고 UI를 다시 불러옵니다.
아래는 몇 가지 유용한 확장 기능들입니다. 이 가이드에 있는 코랩을 사용중이라면 대부분을 사용해 본 것들이겠지만 위의 2개는 직접 추가해서 사용하는 것을 추천합니다.
이미지 브라우저(Image Browser) - 과거에 생성된 이미지를 매우 효율적으로 탐색할 수 있을 뿐만 아니라 해당 이미지의 프롬프트와 매개변수를 txt2img, img2img 등으로 보낼 수 있습니다.
태그 완성(TagComplete) - 애니메이션 그림체에 필수적인 기능입니다. 입력할 떄 일치하는 부루(booru) 태그를 보여줍니다. 애니메이션 모델은 부루 태그를 통해 작동하며, 부루 태그가 없는 프롬프트는 일반적으로 작동하지 않으므로 부루 태그를 알고 있다는 것은 엄청난 것입니다. 하지만 모든 태그가 모든 모델에서 잘 작동하는 것은 아니고 드물게 나오는 태그는 더더욱 잘 작동하지 않습니다.
Locon - Locon과 LoHa를 사용할 수 있습니다. 자세한 내용은 아래에서 확인해보세요.
컨트롤넷 - 자체 가이드가 필요할 정도로 큰 확장 기능입니다. 모든 이미지를 분석해 자신의 이미지에 대한 참조로 사용할 수 있습니다. 실제로 원하는 포즈나 환경을 만들 수 있습니다.
끝판왕 업스케일러(Ultimate Upscale) - img2img 부분에서 아주 큰 이미지를 만드는데 사용하는 확장 기능으로 일반적으로 VRAM이 허용하는 최대 크기까지 만들 수 있습니다. 자세한 것은 아래에서 확인해보세요.
투 샷(Two-shot) - 일반적으로 같은 이미지에 둘 이상의 캐릭터를 만들 수 없습니다. 이 확장 기능을 사용하면 이미지의 전체, 왼쪽, 오른쪽 부분으로 분할해 두 캐릭터가 있는 이미지를 만들 수 있습니다.
모델 변환기(Model Converter) - safetensors. fp16, no-ema를 선택하여 대부분의 4GB, 7GB 모델을 2GB로 변환할 수 있습니다. 이러한 가지치기된(pruned) 모델은 풀(full) 모델과 '거의 동일하게' 작동합니다. 즉 수학적인 이유로 인해 눈에 띄는 차이가 없습니다. 요즘에는 대부분의 모델들이 2GB로 나옵니다.
LoRA
LoRA(Low-Rank Adaptation) 는 엑스트라 네트워크의 한 형태이며 전체 모델에 일종의 작은 모델을 추가할 수 있는 최신 기술입니다. 앞서 살펴본 임베딩과 비슷하지만 LoRA는 더 크고 더 많은 기능을 제공합니다. 기술적인 세부 사항은 생략하도록 하겠습니다.
LoRA는 캐릭터, 그림체, 자세, 옷, 심지어는 사람의 얼굴까지 표현할 수 있습니다. 일반적인 작업에는 체크포인트로도 충분하지만, 기존 사례가 거의 없는 구체적인 디테일에 관해서는 LoRA가 필요합니다. LoRA는 civitai와 그 외의 곳(NSFW) 에서 다운로드할 수 있으며, 기본적으로 용량이 144MB이지만 1MB까지 낮출 수 있습니다. 용량이 크다고 해서 항상 좋은 것은 아닙니다. 대부분의 체크포인트와 마찬가지로 *.safetensors 형식으로 제공됩니다.
stable-diffusion-webui/models/Lora 폴더에 LoRA 파일을 넣거나 이 가이드에 있는 코랩을 사용하는 경우 custom_urls 텍스트 상자에 직접 다운로드 링크를 붙여놓기 해줍니다. 그런 다음 생성(Generate) 버튼 아래에 있는 추가 네트워크 표시 버튼(🎴) 을 눌러줍니다. 바로 아래 또는 맨 아래에 새 부분이 열립니다. LoRA 탭을 클릭하고 새로 고침 버튼을 눌러 새 LoRA를 검색합니다. 해당 메뉴에서 LoRA를 클릭하면 다음과 같이 프롬프트에 LoRA가 추가됩나다: <lora:파일명:1>. 시작은 항상 동일합니다. 파일 이름은 *.safetensors 확장자가 없는 시스템의 정확한 파일 이름입니다. 마지막으로 숫자는 앞서 본 것처럼 가중치입니다. 대부분의 LoRA는 0.5에서 1 사이의 가중치에서 작동하며, 특히 여러 LoRA를 동시에 사용하는 경우 값이 너무 높으면 이미지가 '튀겨질' 수 있습니다.
LoRA의 예시로 두꺼운 선을 쓴 애니메이션 스타일이 있는데, 이는 이미지가 전통적인 애니메이션처럼 보이기를 원하는 경우 완벽합니다.
LyCORIS
LyCORIS는 LoRA가 더 많은 레이어를 학습할 수 있도록 하는 새롭게 개발된 것입니다. 여기에서 자세히 알아보세요. LyCORIS를 사용하기 위해서는 확장 기능이 필요합니다.
현재 LoRA의 새로운 유형은 아래의 2가지입니다
LoCon - 스타일에 좋음
LoHa - 캐릭터가 포함된 스타일에 좋음
트레이너 아래에서 독자만을 위한 학습도 가능합니다.
* 원본 글에 해당 내용 없음, 추후 추가될 수도 있음
업스케일링
매개변수 생성에서도 언급한것처럼 일반적으로 이미지를 생성할 때는 너비 또는 높이가 768 픽셀을 넘지 않아야 합니다. 대신 업스케일러와 적절한 노이즈 제거 수준을 선택할 때 Hires fix을 사용해야 합니다. 그러나 Hires fix는 VRAM 제한을 받으므로 끝판왕 업스케일러를 통해 더 크게 확장하는데 관심이 있을 수 있습니다.
추가 업스케일러는 다운로드 해서 stable-diffusion-webui/models/ESRGAN 폴더에 넣을 수 있습니다. 그러면 Hires fix, 끝판왕 업스케일러, 추가 가능에서 사용할 수 있습니다.
이 가이드에 있는 코랩에서는 모든 종류의 이미지에 적당한 만능 업스케일러인 Remacri를 포함한 여러 종류가 코랩에 있습니다.
몇 가지 주목할 만한 업스케일러는 여기에서 찾을 수 있습니다.
LDSR은 고품질이지만 느린 업스케일러이며 모델과 설정은 여기에서 찾을 수 있고 stable-diffusion-webui/models/LDSR 폴더에 둬야합니다.
일반적으로 똑같은 시드를 사용하지만 원하는 매개변수를 변경하여 일련의 이미지를 생성할 수 있습니다. 다양한 모델, 프롬프트의 일부, 샘플러, 업스케일러 등 원하는 거의 모든 것을 비교할 수 있습니다. 가변 파라미터를 1개, 2개, 3개(X, Y, Z)로 설정할 수 있습니다.
X/Y/Z 플롯의 매개변수는 쉼표로 구분되지만 그 사이에 다른 매개변수를 넣을 수 있습니다. 비교하는 가장 일반적인 매개변수는 S/R 프롬프트이며, 첫 번째 용어는 프롬프트의 문구이고 그 이후의 각 용어는 원본을 대체합니다. 이것을 알면 아래와 같이 LoRA 강도를 비교할 수 있습니다.
팁: 다음과 같이 따옴표를 사용하여 쉼표로 S/R을 표시할 수 있습니다(쉼표와 따옴표 사이에는 공백을 두지 않음): "term 1, term 2","term 3, term 4","term 5, term 6"
프롬프트 매트릭스
개념적으로는 앞서 본 S/R과 비슷하지만 더 심층적입니다. 프롬프트의 | 기호 사이에 나열된 가능한 모든 용어 조합을 표시하는 방식으로 작동합니다. 예로 young man|tree|city 에는 항상 'young man'이 포함되지만 'tree'와 'city'를 추가하거나 제거하면 어떤 일이 발생하는지 살펴볼 것입니다. 기호 사이에는 쉼표와 공백을 사용할 수 있습니다.
스크립트 내에서 행렬을 만들 프롬프트, 네거티브 프롬프트 중 하나를 선택하고 변수 조건을 시작, 끝에 넣을지 여부를 선택합니다.
다음은 프롬프트 부분에서 설명드린 네거티브 프롬프트를 이용한 비교입니다. EasyNegative가 이미지에 어떤 영향을 미치는지, 나머지 프롬프트가 이미지에 어떤 영향을 미치는지, 그리고 두 프롬프트가 이미지에 어떤 영향을 미치는지 함께 확인할 수 있습니다.
팁: 프롬프트 매트릭스를 사용할 때 배치 크기를 사용하면 여러 이미지 또는 전체 그리드를 한 번에 생성할 수 있습니다.
끝판왕 업스케일러
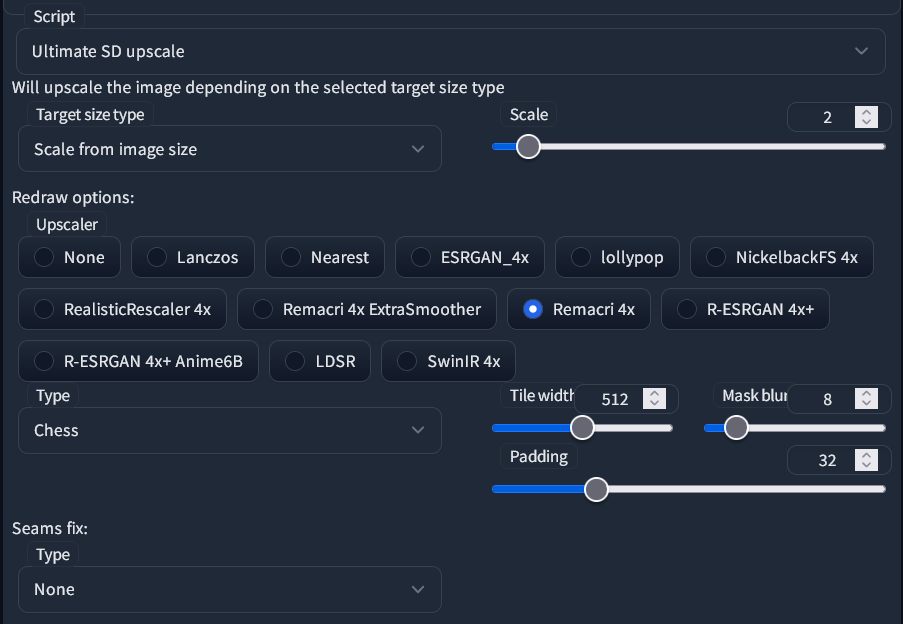
내장 스크립트의 개선 버전으로 확장 기능으로 추가하여 img2img 내에서 사용할 수 있습니다. 이 스크립트의 목적은 이미지의 크기를 조정하고 느리지만 이미지를 여러 덩어리로 나눠 VRAM의 일반적인 한계를 넘는 더 많은 디테일을 추가하는 것입니다. 방법은 아래와 같습니다.
1. 일반적으로 최대 768 픽셀의 너비와 높이를 가진 이미지를 생성한 다음 가능한 경우 hires fix을 적용할 수 있습니다.
2. txt2img 또는 이미지 브라우저 확장 프로그램에서 프롬프트와 매개변수를 img2img로 직접 전달합니다.
3. Denoising을 0.1~0.4로 설정합니다. 더 높은 값을 주면 현대 미술이 나올 가능성이 높습니다.
4. 스크립트로 이동하여 Ultimate SD Upscale을 선택합니다. 그런 다음 원하는 크기와 업스케일러 'Chess' 타입을 사용하여 매개변수를 아래와 같이 설정합니다.
VRAM이 충분하다면 타일의 타일 너비(Tile width) 와 패딩(Padding) 값을 늘릴 수 있습니다. 예를 들어서 두 값 다 2배입니다. 타일 높이(Tile height)에 0을 넣으면 너비와 같은 값으로 적용됩니다.
최종 이미지에서 영역간에 눈에 띄는 이음새가 발생하지 않는 한 Seams fix을 설정할 필요가 없습니다.
5. 이미지를 생성하고 기다립니다. 이미지 미리보기를 활성화 한 경우 사각형이 선명해져 가는것을 볼 수 있습니다.
컨트롤넷(ControlNet)
컨트롤넷은 스테이블 디퓨전을 위한 아주 강력한 최신 기능입니다. 이 기능을 사용하면 기존에 존재하는 모든 이미지에 대한 정보를 분석하여 AI 이미지 생성에 활용할 수 있습니다. 이것이 의미하는 것은 아래에서 다시 살펴보겠습니다.
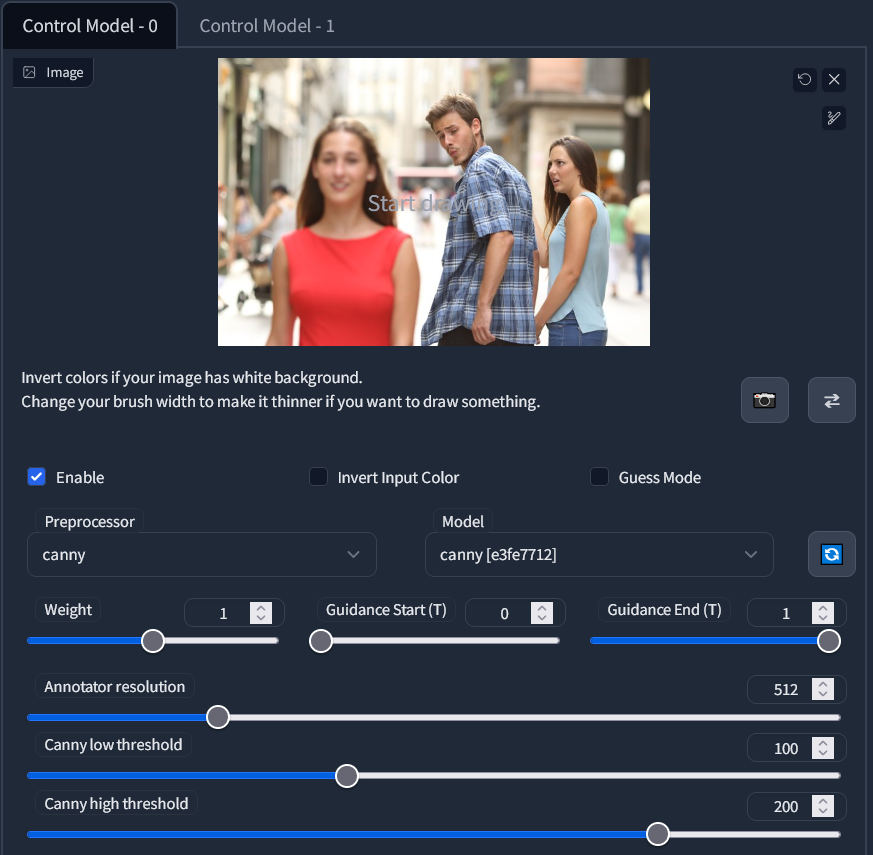
이 글에 있는 코랩을 사용하는 경우 all_control_models 옵션을 활성화 해야합니다. 그렇지 않은 경우 컨트롤넷 확장 기능을 설치한 다음 여기로 이동해서 stable-diffusion-webui/extensions/sd-webui-controlnet/models 경로에 둬야 할 몇 가지 모델을 다운로드 해야합니다. 이 글에서는 Canny, Depth, Openpose, Scribble을 추천합니다.
컨트롤넷 사용 방법을 보여드리겠습니다 이를 위해 온라인에서 인기 있는 샘플 이미지로 선택했습니다. 이대로 따라할 필요는 없지만 이미지를 다운로드 하여 PNG Info 탭에 넣으면 생성 데이터를 볼 수 있습니다.
먼저 txt2img 페이지에서 아래로 내려서 ControlNet을 클릭하여 메뉴를 열어야 합니다. 그런 다음 Enable을 누르고 일치하는 Preprocessor와 Model을 선택해줍니다. 저는 이 두가지 모두에 Canny를 사용해 보겠습니다. 마지막으로 샘플 이미지를 업로드 해줍니다. 샘플 이미지를 누르지 않으면 그리기가 시작합니다. 다른 설정은 무시해도 됩니다.
Canny
Canny 방법은 샘플 이미지의 테두리 부분을 추출합니다. 다양한 유형의 이미지, 특히 작은 세부 사항과 이미지의 일반적인 모양을 보존하려는 경우에 유용합니다.
Scribble을 제외한 각 방법에 대해 2가지 결과가 있음을 알 수 있습니다. 첫번째는 전처리된 이미지라고 하는 중간 단계로, 최종 이미지를 생성하는데 사용합니다. 전처리된 이미지를 직접 제공할 수 있으며 이 경우에는 Preprocessor를 None으로 설정해야 합니다. 이 기능은 블렌더(Blender) 나 포토샵(Photoshop) 과 같은 외부 도구에서 아주 강력합니다.
설정 탭에서는 여러개의 컨트롤넷은 한번에 활성화 할 수 있는 컨트롤넷 섹션이 있습니다. 특정 환경에서 특정 캐릭터의 자세를 취하거나 특정 손동작이나 디테일을 얻기 이해 Openpose를 사용할 때 유용하게 사용할 수 있습니다.
데이터세트에 태그를 지정하려면 WEBUI용 WD1.4Tagger 확장 프로그램을 사용해보세요. 먼저 확장 프로그램을 추가하고 할성화 한 다음 전체 WEBUI를 재시작합니다. Tagger 탭으로 이동한 다음 디렉토리에서 배치를 선택하고 이미지가 있는 폴더를 선택합니다.출력 이름을 [name].txt로 설정하고 임계값(threshold)을 0.35 이상으로 설정합니다. 그런 다음 Interrogate 버튼을 누르면 텍스트 파일 생성이 시작됩니다.
이 가이드와 같이 대그를 큐레이션 하려면 WEBUI용 태그 편집기 확장 프로그램을 사용하세요. 태그 정렬, 가지치기, 바꾸기, 병합 등 필요한 모든 기능을 갖고 있습니다. 활성화 태그를 추가하는 방법은 이렇습니다: 확장 프로그램을 추가하고 WEBUI를 다시 시작한 뒤 Dataset Tag Editor 탭으로 이동한 다음 Batch Edit Captions으로 이동합니다. 'Show only the tags...' 를 끄고 'Prepend additional tags'를 켠 다음 Edit Tags 텍스트 상자에 활성화 태그를 추가합니다. 그런 다음 변경 사항을 적용하기 위해 위로 스크롤하여 올린 다음 Save all changes를 눌러줍니다. 그래야만 파일이 수정되고 모든 텍스트 파일의 시작 부분에 새 태그가 추가됩니다.
드림부스(Dreambooth) 는 빨리 과적합(과대적합) 되는 경향이 있습니다. 좋은 품질의 이미지를 얻으려면 학습 단계(Training Stpes) 와 학습률(Learning Rate) 사이에서 '최적점'을 찾아야 합니다. 낮은 학습률을 사용하고 결과가 만족스러울 때 까지 학습 단계 수를 점진적으로 늘리는 것이 좋습니다.
드림부스는 얼굴에 대해 더 많은 학습이 필요합니다. 실험 결과 배치 크기(batch size) 를 2로 설정하고 학습률을 1e-6(0.000001) 으로 설정하고 800~1,200 단계에서 잘 작동했습니다.
얼굴을 학습할 때 과적합을 방지하려면 사전 보존이 중요합니다. 다른 피사체의 경우 큰 차이가 없는 것 같습니다.
생성된 이미지에 노이즈가 있거나 품질이 저하된 경우 과적합이 되었을 수도 있습니다. 먼저 위의 단계를 시도하여 과적합을 방지하십시오. 생성된 이미지에 여전히 노이즈가 있는 경우 DDIM 스케쥴러를 사용하거나 더 많은 추론 단계를 실행하세요.(실험에서 100개 까지는 잘 작동함)
U-Net과 텍스트 인코더(Text Encoder) 를 학습시키면 품질에 큰 영향을 미칩니다. 텍스트 인코더의 미세 조정, 낮은 학습률, 적절한 단계수를 사용하여 최상의 결과를 얻었습니다. 그러나 텍스트 인코더를 미세 조정하려면 더 많은 VRAM이 필요하고 최소 24GB 이상의 VRAM이 있는 GPU가 이상적입니다. 8bitAdam, fp16 학습 또는 구글 코랩(Google Colab) 또는 캐글(Kaggle) 에서 제공하는 것과 같은 16GB VRAM을 가진 GPU에서 학습할 수 있습니다.
EMA를 사용하거나 사용하지 않고 미세 조정하면 비슷한 결과가 나옵니다.
드림부스를 학습시키기 위해 sks 토큰을 사용할 필요는 없습니다. 첫 번째 구현 중 하나는 어휘에서 드문 토큰이기에 사용했지만 실제로는 일종의 라이플입니다. 우리의 실험과 @nitrosocke의 실험은 대상을 설명할 때 자연스럽게 사용할 수 있는 용어를 선택해도 괜찮다는 것을 보여줍니다.
학습률이 미치는 영향
드림부스는 아주 빠르게 과적합됩니다. 좋은 결과를 얻으려면 데이터 세트에서 적합한 방식으로 학습률과 훈련 단계 수를 조정하십시오. 실험(후술) 에서는 학습률이 높거나 낮은 4가지 데이터 세트에 대해 미세조정하였습니다. 모든 경우에서 낮은 학습률이 더 나은 결과를 보였습니다.
실험 설정
2대의 TESLA A100 40GB에서 AdamWOptimizer을 활성화하고 train_dreambooth.py 스크립트를 사용하여 실험했습니다. 동일한 시드값을 사용했으며 학습률, 훈련 단계 수, 사전 보존 사용을 제외한 모든 하이퍼파라미터를 동일하게 사용했습니다.
처음 3개의 예제(다양한 오브젝트) 의 경우, 400단계에 대해 배치 크기를 4(GPU당 2) 로 모델을 미세 조정했습니다. 학습률은 5e-6(0.000005)의 높은 속도, 2e-6(0.000002)의 낮은 속도를 사용했습니다. 사전 보존은 사용하지 않았습니다.
마지막 실험에서는 모델에 인간 피사체를 추가하려 시도합니다. 이 경우 배치 크기를 2(GPU당 1), 800단계와 1,200단계의 사전 보존을 사용했습니다. 학습률은 5e-6(0.000005)의 높은 속도, 2e-6(0.000002)의 낮은 속도를 사용했습니다.
8-bit Adam, fp16 학습, Gradient Accumulation을 사용해 메모리 사용량을 줄이고 16GB의 VRAM을 가진 GPU에서 비슷한 실험을 할 수 있다는 점을 유의하세요.
장난감 고양이
높은 학습률 5e-6(0.000005)
낮은 학습률 2e-6(0.000002)
돼지 머리
높은 학습률 5e-6(0.000005)
색상 아티팩트는 노이즈 잔여물이고 추론 단계를 더 실행하면 이런 세부 사항을 해결하는데 도움이 될 수 있습니다.
낮은 학습률 2e-6(0.000002)
미스터 포테이토
높은 학습률 5e-6(0.000005)
색상 아티팩트는 노이즈 잔여물이고 추론 단계를 더 실행하면 이런 세부 사항을 해결하는데 도움이 될 수 있습니다.
낮은 학습률 2e-6(0.000002)
사람의 얼굴
우리는 시트콤 '사인필드(Seinfeld)'에 나오는 크레이머(Kramer) 캐릭터를 스테이블 디퓨전에 통합하려 했습니다. 앞서 언급한것처럼 우리는 더 작은 배치로 더 많은 단계를 훈련했습니다. 그럼에도 불구하고 결과는 좋지 않았습니다. 간결성을 위해 이러한 샘플 이미지는 생략하고 다음 부분으로 넘어가서 얼굴 훈련에 대해 집중적으로 설명하겠습니다.
초기 결과 요약
드림부스로 스테이블 디퓨전을 훈련하여 좋은 결과를 얻으려면 데이터 세트의 학습 속도와 훈련 단계를 조정하는 것이 중요합니다.
학습률이 높고 훈련 단계가 너무 많으면 과대적합이 될 수 있습니다. 모델은 어떤 프롬프트를 사용하던 대부분을 훈련한 데이터에서 이미지를 생성합니다.
학습률이 낮고 훈련 단계가 너무 낮으면 모델이 통합하려는 개념을 생성할 수 없는 과소적합으로 이어집니다.
얼굴은 훈련하기 더 어렵습니다. 실험 결과 사물의 경우 훈련 단계 400번에 2e-6(0.000002)의 학습률이 효과적이었지만 얼굴의 경우 훈련 단계 1,200번에 1e-6(0.000001) ~ 2e-6(0.000002)의 학습률이 필요했습니다.
모델이 과대적합되면 이미지 품질이 크게 떨어지고 다음과 같은 경우에 발생됩니다
학습률이 너무 높은 경우
훈련 단계가 너무 많은 경우
얼굴의 경우 다음 부분에 있는것처럼 사전 보존이 사용되지 않은 경우
얼굴 훈련시 사전 보존 사용
사전 보존은 미세 조정 과정의 일부로 훈련하려는 동일한 클래스의 추가 이미지를 사용하는 기술입니다. 예를 들어서 새로운 사람을 모델에 통합하려고 할 때 보존하려는 클래스는 사람일 수도 있습니다. 사전 보존은 새로운 사람의 사진과 다른 사람의 사진을 결합하여 과대적합을 줄이려고 합니다. 좋은 점으로는 안정 확살 모델 자체를 사용하여 이러한 추가 클래스 이미지를 생성할 수 있다는 것입니다! 원하는 경우 훈련 스크립트가 자동으로 처리하지만 사용자가 직접 사전 보존 이미지가 포함된 폴더를 제공할 수 있습니다.
사전 보존을 사용한 경우, 1,200단계, 학습률 2e-6(0.000002)
사전 보존을 사용하지 않는 경우, 1,200단계, 학습률 2e-6(0.000002)
보이는것처럼 사전 보존을 사용하면 결과가 더 좋아지지만 여전히 노이즈와 같은 얼룩들이 보입니다. 이제 몇가지 트릭들을 사용할 차례입니다!
스케줄러의 효과
이전 예제에서는 추론 프로세스 중에 PNDM 스케줄러를 사용하여 이미지를 샘플링했습니다. 모델이 과대적합일 때 DDIM이 일반적으로 PNDM, LMSDiscrete보다 훨씬 더 잘 작동하는 것을 관찰했습니다. 또한 더 많은 단계에 대해 추론을 실행하면 품질이 향상될 수 있고 100단계가 좋은 선택인 것 같습니다. 추가 단계는 일부 노이즈 패치를 이미지 디테일로 해결하는데 도움이 됩니다.
PNDM을 이용한 크레이머 훈련
LMSDiscrete을 이용한 크레이머 훈련, 결과는 아주 거지같습니다
DDIM을 이용한 크레이머 훈련, 훨씬 낫습니다
차이는 덜하지만 다른 사물들도 비슷한 결과를 보였습니다.
PDPM을 이용한 미스터 포테이토 훈련
LMSDiscrete을 이용한 미스터 포테이토 훈련
DDIM을 이용한 미스터 포테이토 훈련
텍스트 인코더 값의 미세 조정
원본 드림부스 논문은 모델의 U-Net 구성 요소를 미세 조정하는 방법을 설명하지만 텍스트 인코더 값은 유지합니다. 하지만 텍스트 인코더 값을 미세 조정하면 더 나은 결과를 얻을 수 있다는 것을 확인했습니다. 다른 드림부스 구현에서 사용되는 것을 보고 이 접근 방식을 실험했는데 결과는 놀라웠습니다!
텍스트 인코더 고정
텍스트 인코더 미세 조정
텍스트 인코더를 미세 조정하면 특히 얼굴에서 최상의 결과를 얻을 수 있습니다. 더 사실적인 이미지를 생성하고 과대적합이 덜 발생하고 더 나은 프롬프트 해석 가능성을 달성하여 더 복잡한 프롬프트를 처리할 수 있습니다.
이 실험에서 먼저 텍스트 반전 2,000단계에 대해 실행했습니다. 그런 다음 이 모델에서 학습률 1e-6을 사용해 추가 500단계 만큼의 드림부스를 실행했습니다. 결과는 다음과 같습니다.
일반 드림부스를 사용하는 것보다 결과가 훨씬 좋지만 전체 텍스트 인코더를 미세 조정하는 것만큼 좋지 않다고 생각합니다. 훈련 이미지의 스타일을 조금 더 복사하는 것 같아서 이미지에 과도하게 맞출 수 있습니다. 이 조합을 더 자세히 살펴보지 않았지만 프림부스를 개선하면서 16GB의 VRAM을 가진 GPU에 프로세스를 맞출 수 있는 흥미로운 대안이 될 수 있습니다.
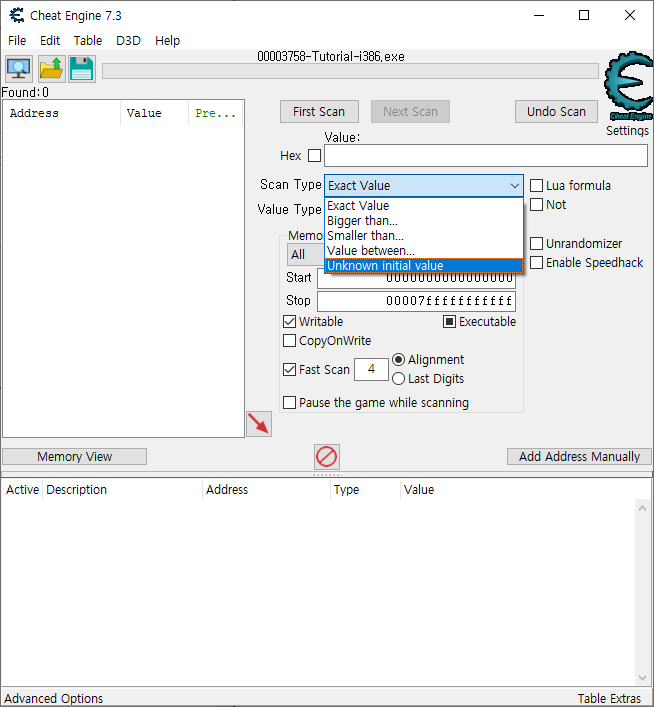
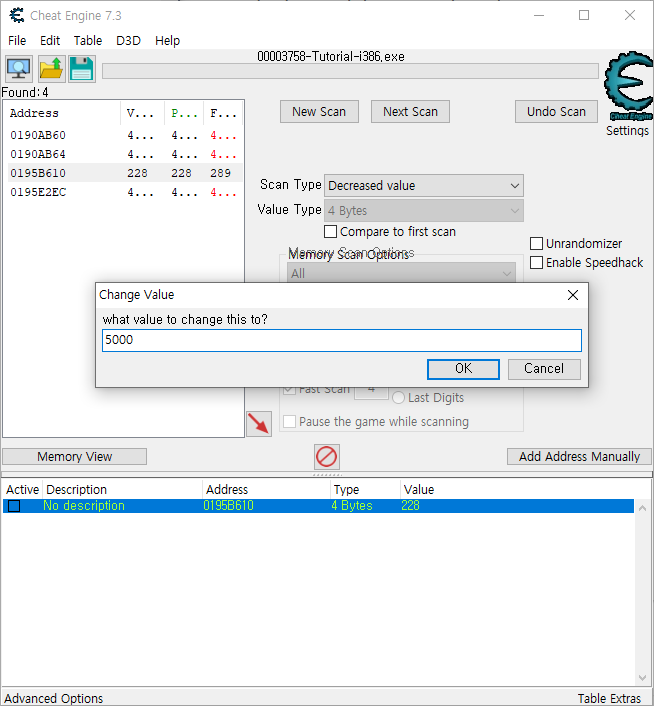
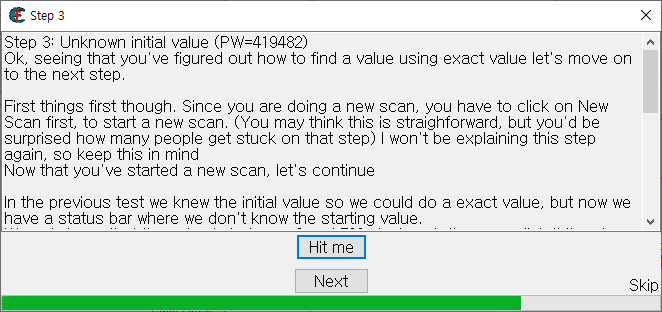
Step 3: Unknown initial value (PW=419482) Ok, seeing that you've figured out how to find a value using exact value let's move on to the next step.
First things first though. Since you are doing a new scan, you have to click on New Scan first, to start a new scan. (You may think this is straighforward, but you'd be surprised how many people get stuck on that step) I won't be explaining this step again, so keep this in mind Now that you've started a new scan, let's continue
In the previous test we knew the initial value so we could do a exact value, but now we have a status bar where we don't know the starting value. We only know that the value is between 0 and 500. And each time you click 'hit me' you lose some health. The amount you lose each time is shown above the status bar.
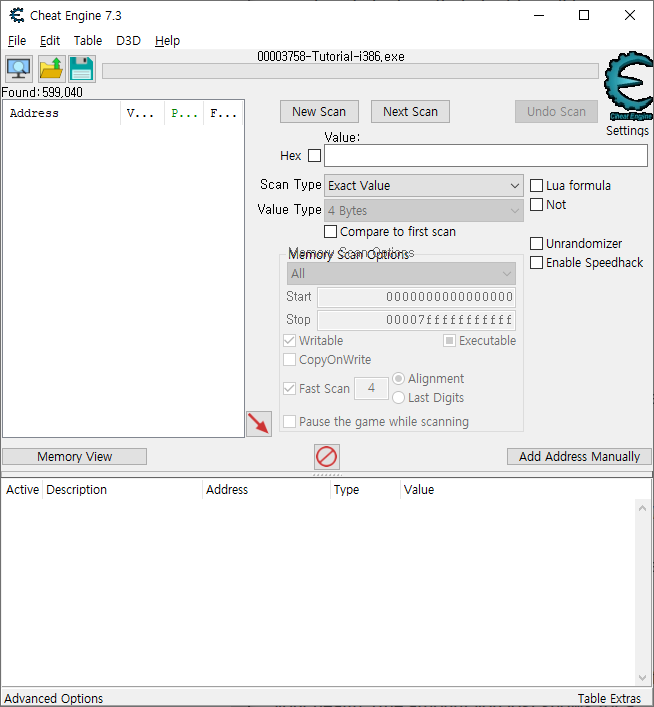
Again there are several different ways to find the value. (like doing a decreased value by... scan), but I'll only explain the easiest. "Unknown initial value", and decreased value. Because you don't know the value it is right now, a exact value wont do any good, so choose as scantype 'Unknown initial value', again, the value type is 4-bytes. (most windows apps use 4-bytes)click first scan and wait till it's done.
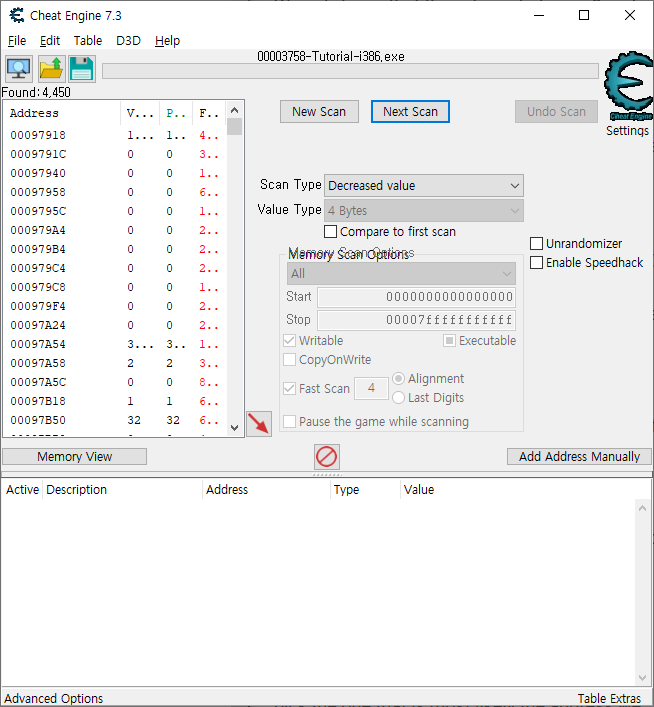
When it is done click 'hit me'. You'll lose some of your health. (the amount you lost shows for a few seconds and then disappears, but you don't need that) Now go to Cheat Engine, and choose 'Decreased Value' and click 'Next Scan' When that scan is done, click hit me again, and repeat the above till you only find a few.
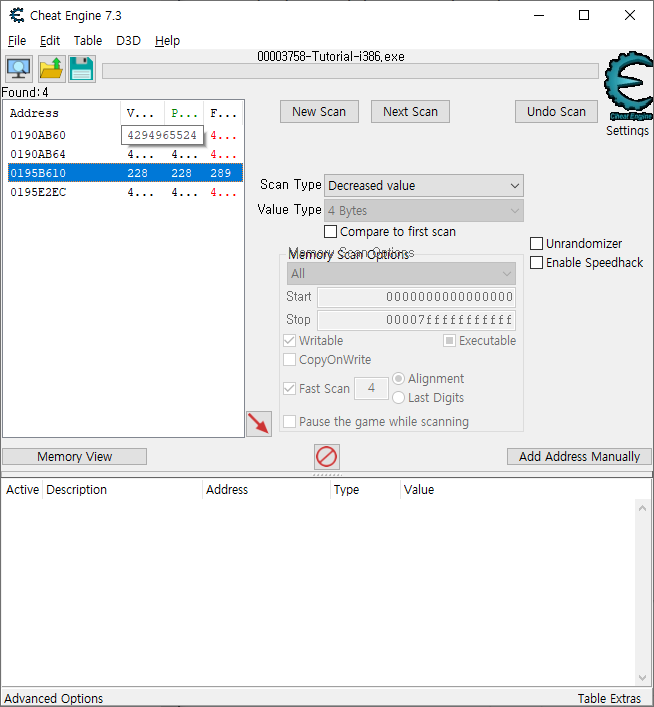
We know the value is between 0 and 500, so pick the one that is most likely the address we need, and add it to the list. Now change the health to 5000, to proceed to the next step.